딥러닝 파이프라인 리팩토링
프로젝트 개발 계기
대학원 입학 후, 연구실과 자주 협업하는 ETRI에서 주최한 논문 경진대회에 참여했다.
다양한 상황의 대화에서 성우 혹은 일반인의 음성, 음성의 자막, 그리고 생리신호가 포함된 데이터셋으로 감정을 분류하고 성과에 대한 논문을 쓰는 경진대회였다.
당시 시간 제약으로 인해 audio, text 2개의 modality만 이용하여 감성을 분류하고자 했고, 각각 pretrained 된 Hubert와 RoBERTa 모델들을 불러와서 경진대회의 데이터셋으로 fine-tune했다.
이후 각 modality에 해당하는 모델에 태워 audio, text embedding vector를 추출 뒤, cross attention transformer를 구축하여 embedding vector끼리 cross attentions을 진행하는 deep fusion을 통해 성능 향상을 도모했다.
결론적으로, 감성 label 당 audio, text의 길이가 짧고, 이미 well-pretrained된 각 modality의 모델에서 추출한 embedding vector들을 cross-attention을 통해 deep fusion하는 것이 오히려 over-fitting으로 성능을 악화시켰다.
fine-tuned single-modality model의 logit 값들을 soft voting하는 shallow fusion이 더 좋은 성능을 내서 해당 결과로 마무리했다.
다만, 이 때 데이터셋의 전처리, 모델의 옵션 등을 바꿔가며 반복 실험을 해야했고, 그 결과를 기록해야했다.
이전에 개인적으로 참여했던 경진대회는 짧은 호흡에 수기로 기록했으나, 본격적으로 구조화된 패키지를 만들어서, yaml 형식의 설정 파일에 옵션을 바꿔주는 것만으로 해당 옵션으로 실험하고 자동으로 기록되길 원했다.
따라서, PyTorch-Lightning, Hydra-Core를 이용하여 구조를 잡아서 설정 파일, 데이터셋과 모델 클래스를 추가 or 수정하는 것만으로 확장 가능한 패키지를 만들었고, 이후 다른 프로젝트들의 기본 구조가 되있다.
딥러닝 파이프라인 프로젝트 업데이트
최근, 지원 받는 서버의 교체로 인해, GPU 종류, OS 및 기타 설정과 가이드라인 변동이 있었고, 거기에 맞춰 라이브러리들을 업데이트해야만 했다.
약 1년 반만의 라이브러리 업데이트로 인해 instantiate에 필요한 arguments들이 바꼈고, 특히 windows -> Ubuntu로 OS 변경으로 인해 DP에서 DDP가 가능해지므로 해당 옵션에 맞춰 수정해야 했다.
주요 버전
코드 및 설정 파일 수정을 야기한 주요 라이브러리 버전(python==3.7.16)
hydra-core==1.3.2
omegaconf==2.3.0
pytorch-lightning==1.9.5
torch==1.13.1
torchmetrics==0.11.4
PyTorch Lightning
버전 업데이트에 따른 Trainer의 인자 옵션, DDP 활용을 위한 LightningModule 구현 변화가 있었다.
Trainer
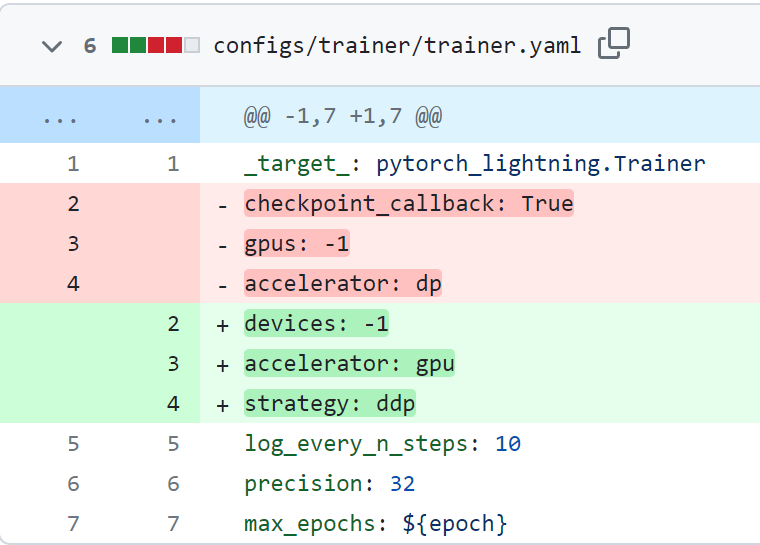
Boolean 타입을 받는 checkpoint_callback 인자가 없어졌다.
Callback을 넣어주면 자동으로 True가 된다.
gpus 옵션의 경우, 기존에 가용할 gpu를 설정하는 옵션이었으나 device로 이름이 바뀌었다(-1 입력 시 가용 가능한 모든 gpu 사용).
accelerator 옵션의 경우, 기존에 DP, DDP 등의 multi-gpu stategy를 설정하는 옵션이었으나 stategy로 이름이 바뀌었고, 현재는 gpu, tpu 등의 가속기를 고르는 옵션이 되었다.
따라서 Trainer를 isntantiate 하기 위한 trainer.yaml을 아래와 같이 수정했다.
DDP
Windows 서버에서는 nccl backend를 지원하지 않아 gloo 등의 다른 backend를 사용하여 많은 실험을 거쳤지만 결국 DDP가 불가능하여 DP를 울며 겨자먹기로 사용했다.
Ubuntu 서버로 바뀌면서 DDP가 가능해져 DDP에 맞게 코드 수정이 필요했다.
- 버전 업데이트에 의해 train/validation/test_step_end function 삭제
DP에서는 step function에서 logging을 하면 rank_zero_only=True로 0번 gpu의 결과만 logging을 해야해서, step_end에서 logging을 하였으나, train/validation/test_step function에서 logging까지 하고, DDP에 따라 sync_dist=True로 줘서 모든 gpu 결과의 평균으로 logging 가능하다.
따라서 아래와 같이 step_end function을 삭제하고, step에서 log 기능을 추가했다.


- 버전 업데이트에 의해 on_epoch_end function 삭제
기존에는 on_epoch_end function에서 metrics를 reset하는 기능을 구현하여, train/validation/test metrics를 모두 on_epoch_end function으로 reset 했다.
버전 업데이트에 따라서 아래와 같이 on_epoch_end function을 각각 train/validation/test_epoch_end function으로 분리하여 구현했다.

TorchMetrics
TocrhMetrics 버전 업데이트에 따른 옵션 변화가 있었다.
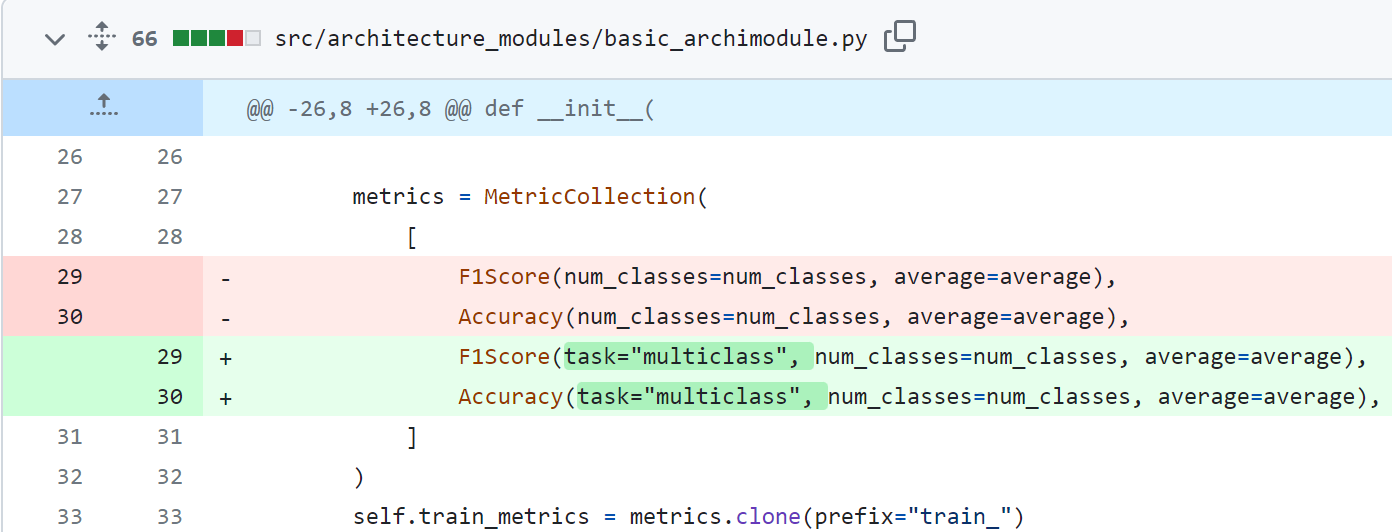
- task 인자 코드에서 추가
TorchMetric 사용 시, task 인자를 반드시 추가해야함에 따라 코드에서 아래와 같이 task 인자를 추가해줬다.
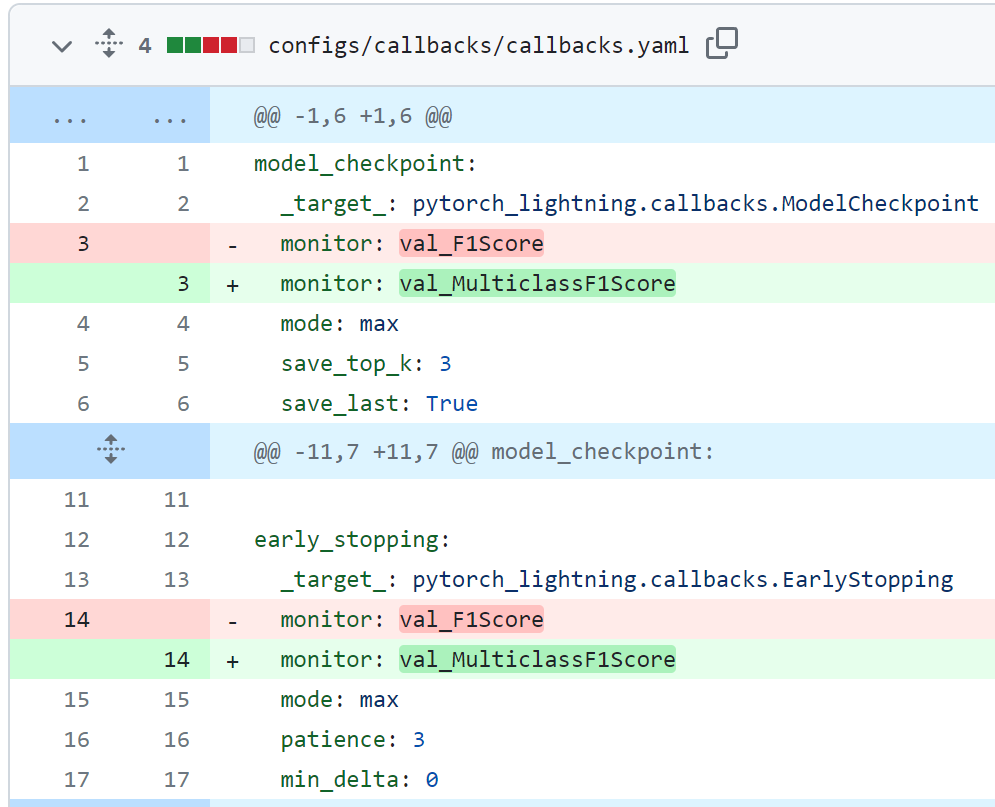
- task 인자에 따른 모니터링 스코어 이름 설정 변경
또한, task에 입력된 옵션이 metric 이름 앞에 붙으므로 callback.yaml 파일의 monitor 이름을 아래와 같이 수정했다.
기타 버전 체크
- hydra-core 버전 체크
hydra-core==1.3.2 omegaconf==2.3.0
해당 버전으로의 조합이 필요하다.
기존에는 hydra를 0.xx의 버전을 사용하다 1.1로 업데이트 했을 때, main 실행 yaml 파일에서 defualts 옵션에서 바로 target으로 시작 후 이후 계층적 선언이 없는 파일끼리 불러올 때 옵션이 꼬이는 문제가 있었다.
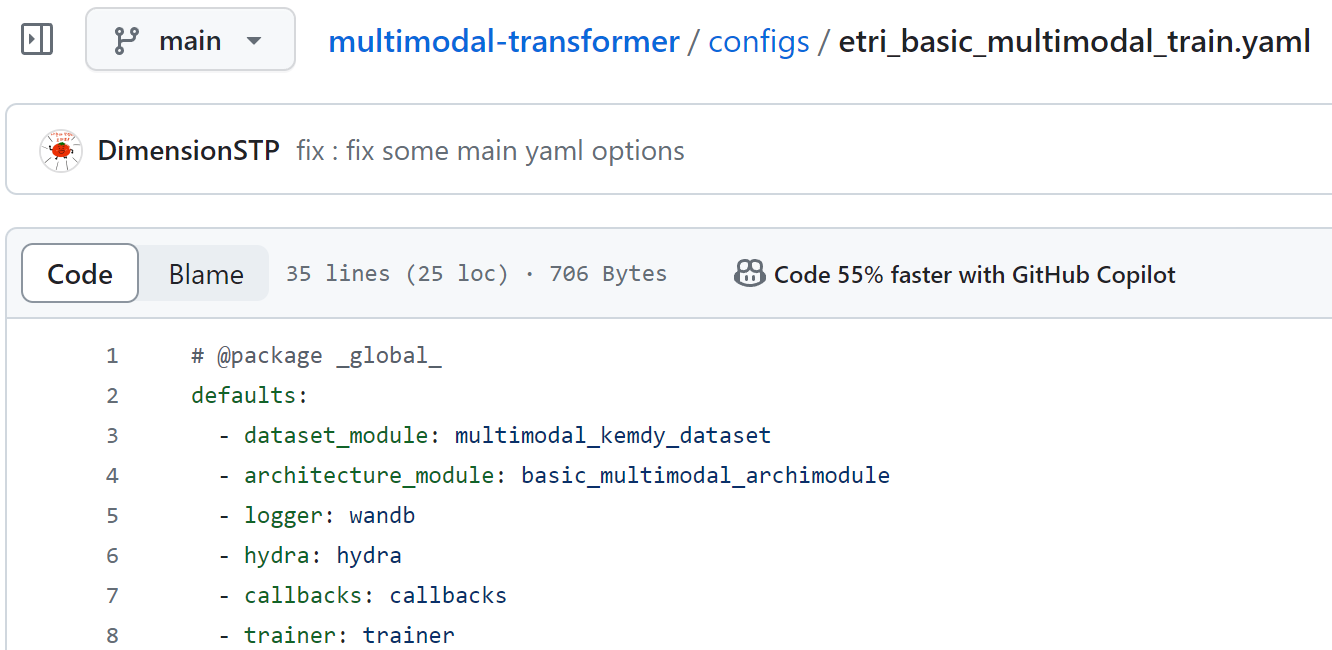
위 main 실행 yaml 파일의 defaults 옵션에서,
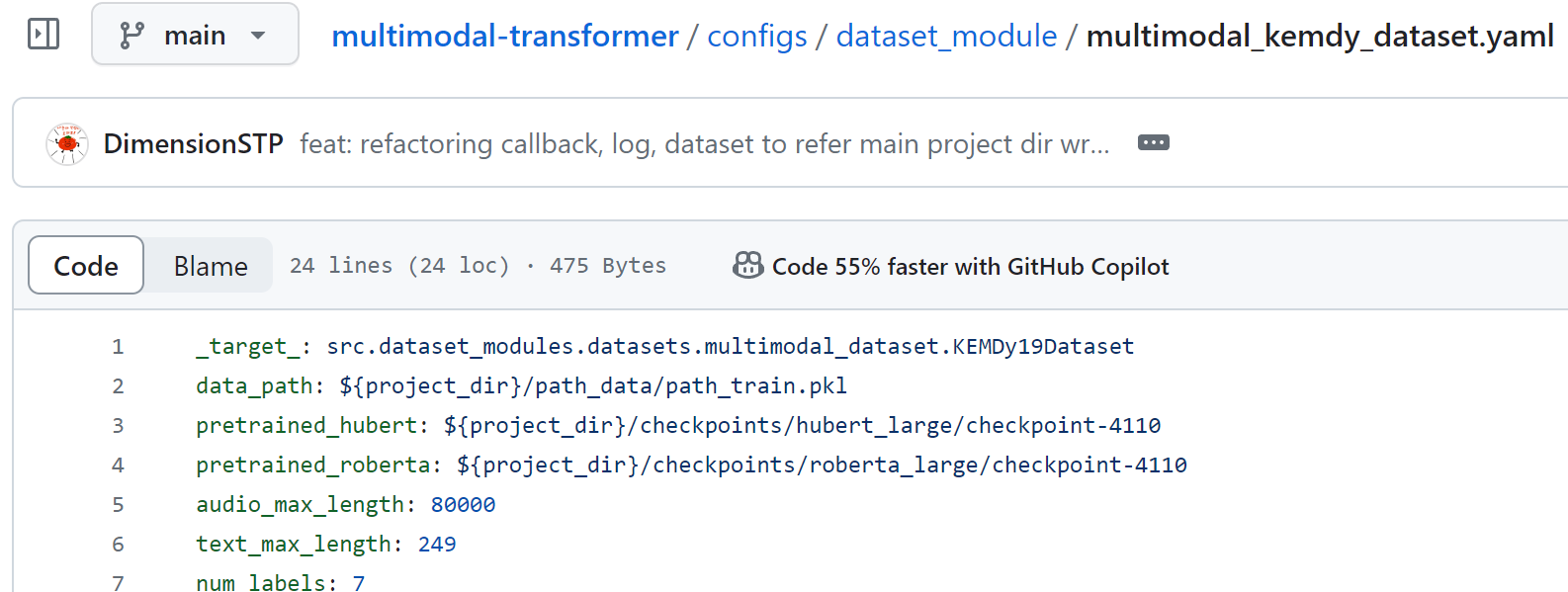
dataset_module과
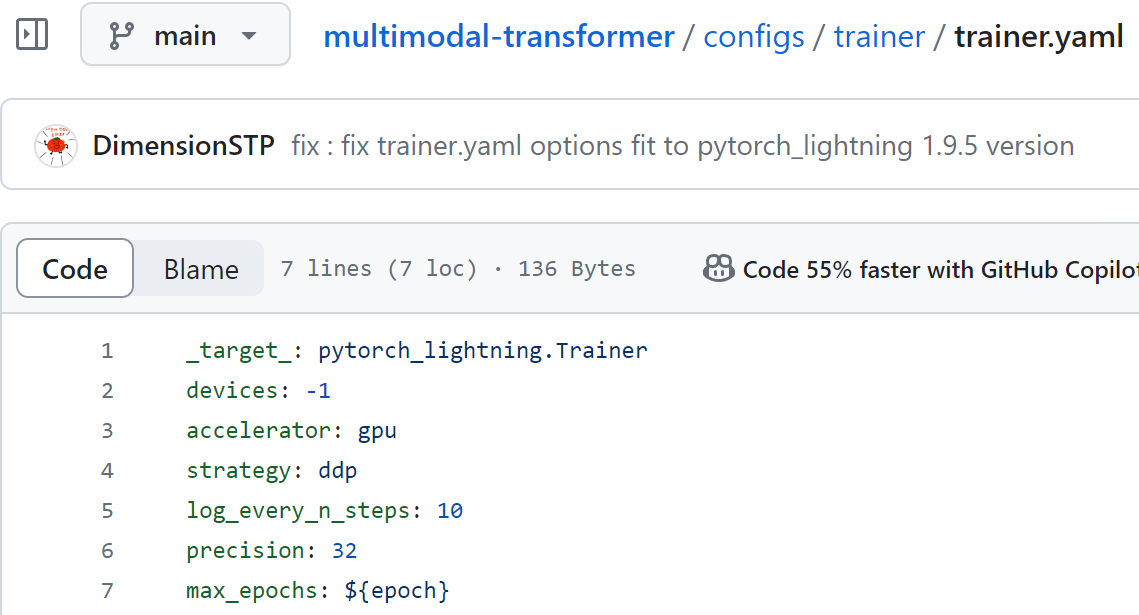
trainer 옵션이 꼬였다.
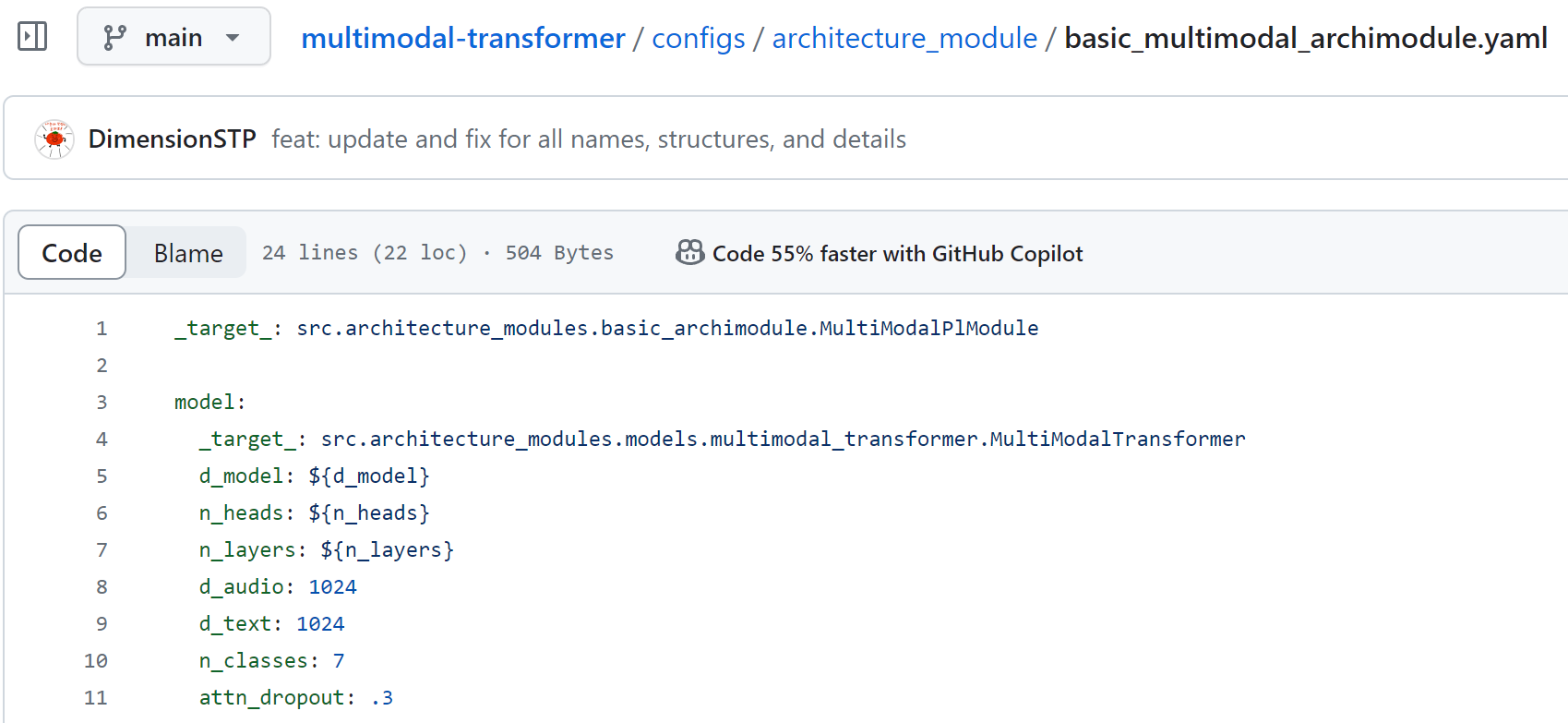
위 architecture_module 같은 경우는 정상적으로 옵션들이 적용됐다.
리팩토링 완료
아래와 같이 모두 정상 실행 및 logging되는 것을 확인했다.

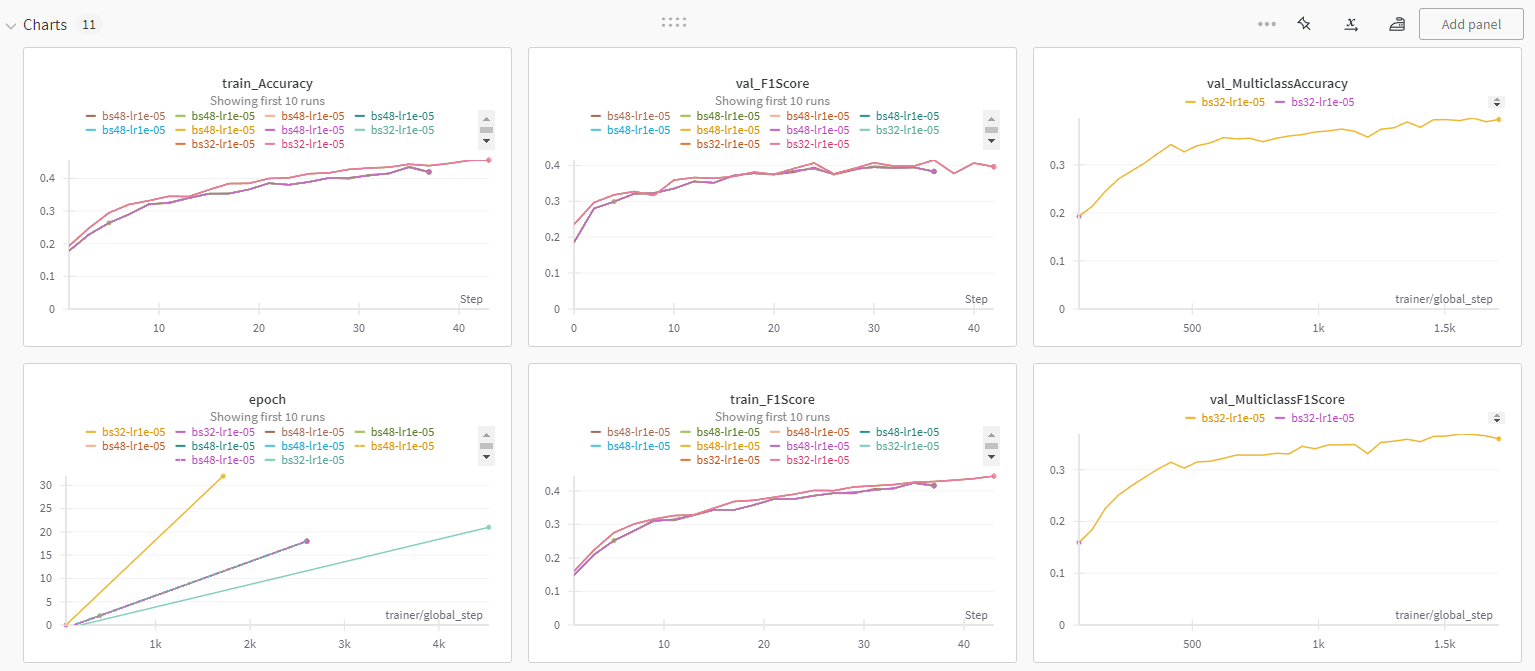
결론
자주쓰는 라이브러리의 경우 주기적인 업데이트에 따른 변경 사항 체크가 필요하다.
하드웨어 환경 변화를 맞이할 때, stable한 버전에 맞춰서 업데이트 및 리팩토링 또한 기존 프로젝트의 구성을 상기하고 개선시킬 수 있는 좋은 경험이다.
댓글남기기