딥러닝, 머신러닝 파이프라인 업데이트
업데이트 계기
업데이트는 끝이 없다. 파이프라인 업데이트 이후, model parallel strategy 등을 공부하며 새로운 사항들을 구현하고, 기존의 문제를 해결하고 싶어졌다.
큰 줄기로 아래 사항들을 구현, 혹은 해결하고 싶었다.
목표
- DeepSpeed strategy의 성능을 최대한 끌어낼 수 있는 optimization
- DeepSpeed strategy와 기존 파이프라인의 완벽한 호환
- Optuna를 이용한 hyper-parameters tuning에서 multi-GPU 사용
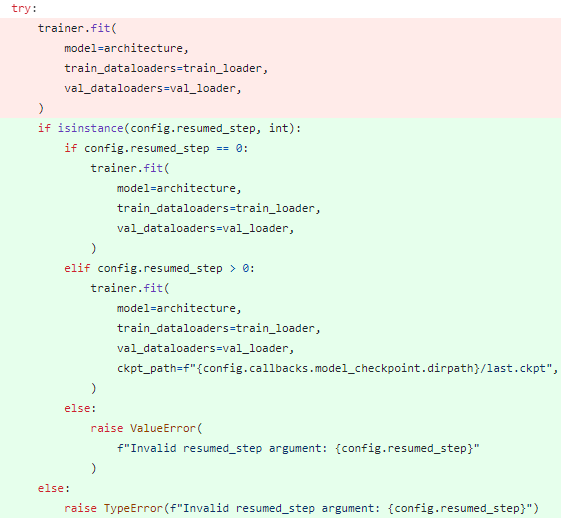
- Training resumption
- 더 나은 WandB projects 관리(실험이 너무 많이 쌓이니 찾아보기 힘듦)
파이프라인 업데이트
파이프라인의 대부분을 업데이트해야 했다.
-
LightningModule에서 configure_optimization method에서 DeepSpeed를 위한 optimizer 설정
- Tuner에서 Multi-GPU를 지원하지 않는 Optuna integration의 PyTorchLightningPruningCallback 제거 및 early stop callback 추가
- Pipeline에서 Training resumption 기능 추가
- Pipeline에서 DeepSpeed Stage 3의 경우 inference 시 single checkpoint file이 아니면 발생하는 에러 해결
- Tuner에서 Callback, Trainer와 중복되는 configs들을 사용하므로 main config로 unification
- Checkpoint 경로 및 명명 방식, Logging project의 mode별 분리를 위한 main config 수정
- 위 사항에 따른 config 파일들 수정
- 기타 레거시 업데이트
주요 라이브러리
주요 라이브러리 버전(python==3.8.x)
hydra-core==1.3.2
omegaconf==2.3.0
lightning==2.2.0
torch==2.2.0
wandb==0.16.3
optuna==3.5.0
deepspeed==0.13.1
DeepSpeed Optimization
DeepSpeed의 경우, offload(GPU memory를 더욱 아끼기 위해 CPU 최적화된 optimizer 사용, GPU-optimizer보다는 느림) 옵션에서 CPU 최적화된 Adam optimizer를 제공하며, 기본 torch의 Adam or AdamW 대비 속도가 꽤 차이난다.
또한, DeepSpeed stage 3의 경우 FusedAdam, offload 시 CPUAdam을 사용할 것을 권장하고 있으므로 해당 조건을 반영했다.

Multi-GPU Hparams Tuning
확인 결과, Optuna의 PyTorchLightningPruningCallback은 Multi-GPU(DDP)가 적용되지 않는다.
Multi-GPU 서버에서 GPU 한장 사용이라니, 이 무슨 손해인가? 차라리 Pruning callback을 쓰지 않는 것이 낫다.
또한 hparams study에 따라 모델 학습 및 capacity에 대한 parameters가 변하는데 고정 epoch를 쓴다는 것 또한 시간적 손해라서, early stop을 추가했다.

Pipeline Module Update
Pipeline에서는 Training Resumption, DeepSpeed 호환 2가지 기능을 추가했다.
Training Resumption
생각해보니 Training에 기존 학습 정보를 불러와서 학습하는 wrapping을 하지 않았다.
따라서, main config 파일에 옵션을 추가하고 해당 옵션에 따라 training resumption 여부 및 단계를 결정하도록 했다.
Resumption 시 PyTorch Lightning에서 단순 model parameters, gradients, optimizer states 뿐만 아니라, 이전 epoch 진행 정도도 불러오기 때문에, epoch 기반으로 model checkpoint를 저장해도 중복이 일어나지 않았다.
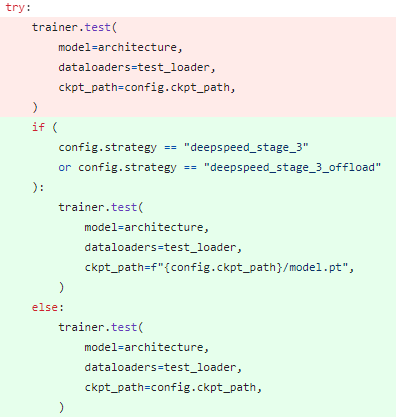
DeepSpeed Strategy at Inference
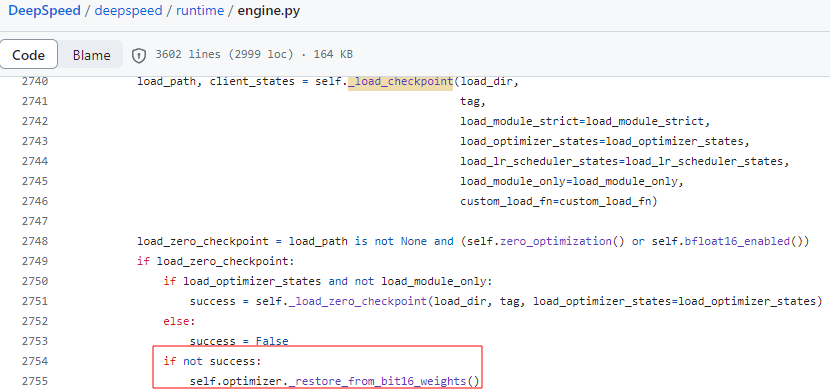
DeepSpeed stage 3의 경우 training에서는 문제가 되지 않으나, inference 시 rank별로 흩어진 model parameters를 합쳐진 파일로 하지 않으면 에러를 뱉는 문제가 있다.
PyTorch Lightning에서 load checkpoint로 DeepSpeed의 load checkpoint를 불러오는데, offload 옵션 여부가 빠져서 if 분기문에서 이상한 곳으로 빠져 에러를 내는 것 같았다.
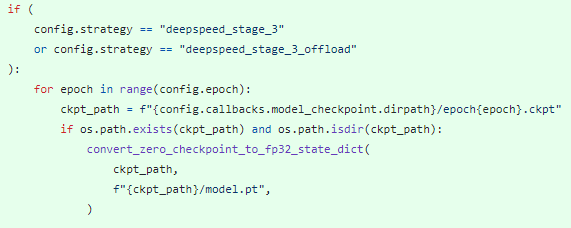
따라서, DeepSpeed stage 3로 학습 시, 학습이 종료되면 해당 경로의 model.pt로 model parameters를 합쳐주고, inference 시에는 합친 파일을 DDP strategy로 불러오도록 했다.
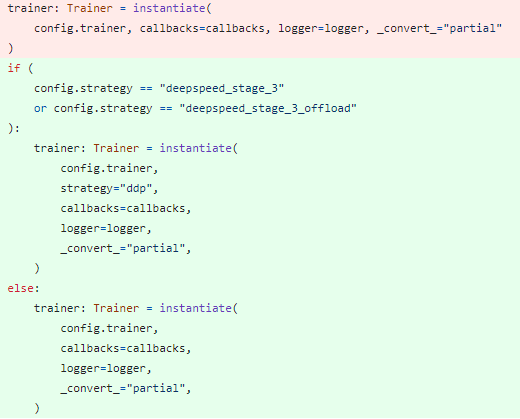
Configs Update
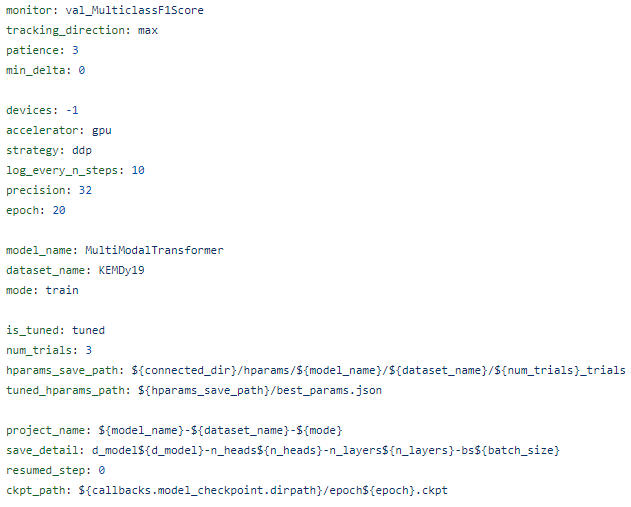
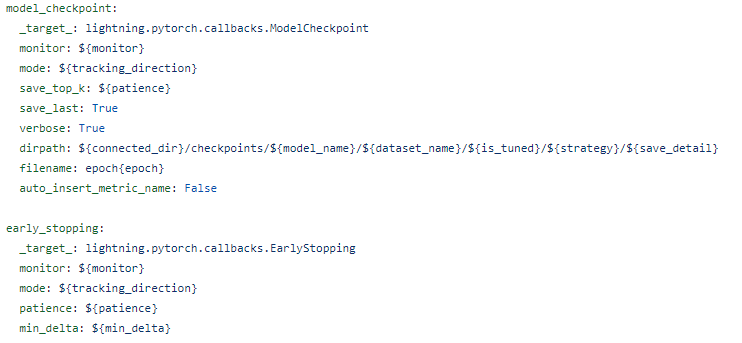
위 구현 사항들에 맞게 .yaml configs도 업데이트 해줬다.
먼저 callback, trainer, tuner의 module_params를 공통적으로 사용해서 다 main config file로 뺐다.
뿐만 아니라, log에서 stratgy에 따른 구분을 넣었고, LightningModule에서도 configure_optimizer의 분기를 strategy로 처리해야 하니 더더욱 그래야 했다.
그 외, logging에서 train, test, tune mode 구분, strategy 추가, checkpoint에서 strategy 추가, model parameters를 폴더로 두고, epoch만 checkpoint 파일 이름으로 하여 가독성을 높이고, 각 실험에 대해 분리가 가능하도록 했다.


ETC
- DataLoader에서 모든 프로젝트에서 train, val, test 구분을 모두 split 옵션으로 통일하고, 기본 옵션을 split.train으로 설정
- LightningModule config에서 DeepSpeed에 따른 optimizer 변경을 위한 strategy 옵션 추가
- README 업데이트
- Shell scripts 업데이트
후기
왜 tag를 붙이고, version을 업데이트하는지 알겠다.
본격적으로 사용하고자 하면 업데이트가 끝이 없다.
원래 각기 다른 환경(version 1.x, 2.x)에 대해 모두 해당 요구 사항을 업데이트하려고 했는데, 일이 너무 많아져서 가장 최근 버전만 업데이트했다.
왜 여러 라이브러리들이 직전 버전에 대한 업데이트만 진행하는지 깨달았다.
프로젝트도 이제 여러 개를 한번에 업데이트를 하려니 공수가 꽤 많이 든다.
새로운 프로젝트 시작 시 DL의 경우 기존 프로젝트를 가져온 후 아래 사항들만 수정하면 된다.
Src
- Model structure 및 Custom loss function, optimizer, metric(필요 시)
- Dataset class 및 Collate_fn(필요 시)
- Model에 따른 Architecture세부 내용
- Model에 따른 Tuner 세부 내용
Configs
- Main config
- Architecture 및 Dataset config
- Callbacks config의 monitor 및 tracking_direction
- Tuner config
그러니 템플릿을 만들어 템플릿만 업데이트 하든, 직전 프로젝트만 업데이트 후 해당 템플릿 혹은 프로젝트를 가져와서 신규 프로젝트의 기반으로 삼는 것이 나을 것 같다.
세부 구현에 대해서는 더 이전 것 중에 필요한 것을 참고하면 될 것이고, 프로젝트가 쌓이다 보면, 자주 쓰는 구현 구조들은 따로 정리해둬도 좋을 것 같다.
댓글남기기