딥러닝, 머신러닝 파이프라인 업데이트
업데이트 계기
한차례 파이프라인 리팩토링을 끝내고 테스트하며 추가로 필요한 부분을 찾아보다가 상세한 logging의 필요성을 발견했다.
Logging에서 고려된 요소
- Model checkpoint name에 들어갈 요소
- Logger(WandB)의 logging name(project name, run name)
- Logging detail(WandB의 run overview - config)에만 기록할 것들
- Log 내역만 보고 해당하는 model checkpoint를 찾을 수 있는가?
- Finished alarm
파이프라인 업데이트
업데이트 계기 자체가 리팩토링된 딥러닝 파이프라인을 다시 train, test 해보다가 필요성을 느낀 것이었다.
기존의 model checkpoint name에 하이퍼 파라미터에 관한 기록이 애매했고, WandB projcet name에 hyper-parameter가 들어가서 애매했으며, 어느 데이터셋으로 학습시켰는지 알 수 없었다.
주요 라이브러리
주요 라이브러리 버전(python==3.7.16)
hydra-core==1.3.2
omegaconf==2.3.0
pytorch-lightning==1.9.5
torch==1.13.1
wandb
optuna==3.4.0
lightgbm
xgboost
Model Checkpoints
이전에는 구현하느라 바빴고, 이후에 반복 실험을 하느라 바빴다.
따라서, 고민을 통해서 규칙을 정하기보다 다른 사람들의 예시를 참고해서 즉석에서 정하고 딱히 수정하지 않았다.
DL에서 기존 저장 방식 예시
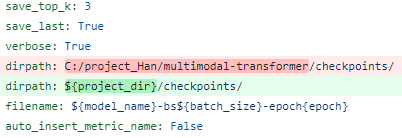
DL에서 개선된 저장 방식 예시
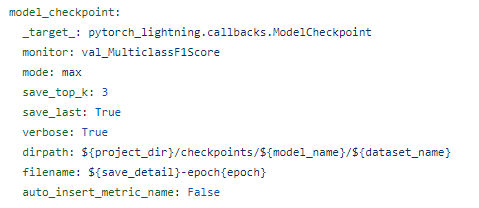

ML에서 저장 방식

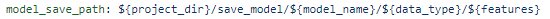
이번에 업데이트하며 코드를 작성하는 시간보다 어떤 요소를 넣을 지 훨씬 고민을 많이 했다.
필수 포함 요소
-
Model name
정확한 모델명 기입.
여러 모델과 task를 한 프로젝트에서 관리하기 위함도 있고, 같은 모델 베이스라도 디테일에 따라 달라지니, 정확한 모델명을 명시할 필요가 있었음.
다만, checkpoint name에 들어가기에는 이름이 너무 길어져서 가독성을 해치니, 폴더로 관리하는 것이 좋다고 생각함.
나중에 다른 학습 데이터셋에 대한 model checkpoint도 폴더로 관리하는 것이 분리하기 쉬울 것이라는 판단.
-
Train dataset
모델이 학습한 데이터셋 기입.
같은 모델이라도 어떤 데이터셋으로 학습했는지, augmentation 여부에 따라 성능이 달라짐.
main.yaml 파일에서 입력하는 데이터셋 이름을 받아오는 형식.
역시 checkpoint name에 들어가기에는 이름이 너무 길어져서 가독성을 해치니, 폴더로 관리하는 것이 좋다고 생각함.
나중에 다른 모델에 대한 model checkpoint도 폴더로 관리하는 것이 분리하기 쉬울 것이라는 판단.
-
모델의 int, categorical hyper-parameters(DL)
PyTorch nn.module로 구현한 모델을 instance화 할 때 들어가는 모든 int, categorical hyper-parameters.
Dropout rate 같은 float type은 model checkpoint name을 지저분하게 만들고, 필수 기입해야 할 만큼 중요하지 않은 것들이 많아서 WandB overview의 config 목록에 logging하고 확인하기로 함.
-
Batch size(DL)
배치 사이즈에 따라 성능의 차이가 나는 경우 존재.
모델 학습 당시의 서버 스펙과 비교하여 추후 활용 가능.
-
Epoch(DL)
보통 early stop을 사용하고, top_k 옵션도 사용해서 필요함.
Epoch에 따른 수렴 정도 유추 가능.
-
Used Features(ML)
ML의 경우, 정형 데이터에서 feature selection을 하기 때문.
최종 저장 이름을 num_folds로만 하기 위해, 폴더로 관리.
-
Fold numbers(ML)
ML의 경우, tuning을 통한 best-params를 이용하여 최종 학습하여 이용하기 때문에, num_folds만 기록해도 충분할 것이라 생각.
WandB Logs
이전의 경우, Project name에 모델의 hyper-parameters 등의 디테일을 다 포함시켰기 때문에, 디테일이 달라지면 project name이 달라지고, project가 갈라져서 비교하기 어려웠다.
기존 로깅 방식 예시
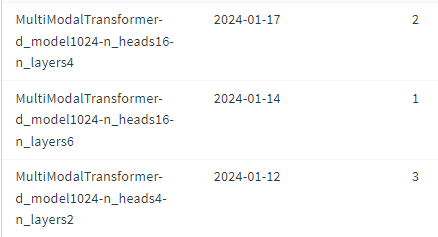
DL에서 개선된 로깅 방식 예시
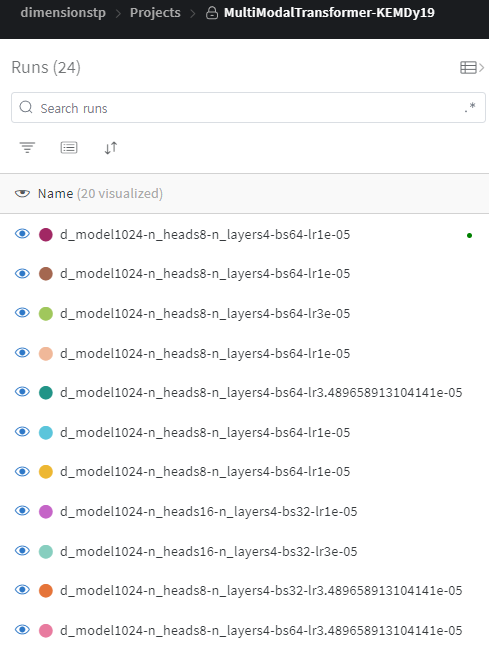
ML에서 개선된 로깅 방식 예시
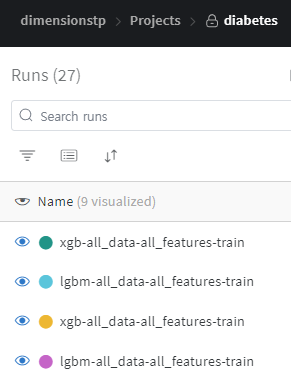
이번에 업데이트하며 project name에 공통으로 묶을 수 있는 필수 요소, run name에 세분화할 수 있는 디테일 요소, overview의 config에 그 외 run name에 기록하기 힘든 추가적인 디테일 요소까지 넣어서 모든 것을 기록하고 비교할 수 있도록 했다.
필수 포함 요소
-
Model name
정확한 모델명 기입.
Project 단위의 공통 요소라고 생각되어 Project name에 {Model name} -{Train dataset} 형식으로 기입.
-
Train dataset
모델이 학습한 데이터셋 기입.
Project 단위의 공통 요소라고 생각되어 Project name에 {Model name} -{Train dataset} 형식으로 기입.
-
모델의 int, categorical hyper-parameters(DL)
PyTorch nn.module로 구현한 모델을 instance화 할 때 들어가는 모든 int, categorical hyper-parameters.
세분화 요소라고 생각되어 Run name에 기입.
Run name - Model checkpoint name을 비교하여 확인하도록 세팅함.
Dropout rate 같은 float type은 model checkpoint name을 지저분하게 만들고, 필수 기입해야 할 만큼 중요하지 않은 것들이 많아서 WandB hyper-parameter 목록에 logging하고 확인하기로 함.
-
Batch size(DL)
배치 사이즈에 따라 성능의 차이가 나는 경우 존재.
모델 학습 당시의 서버 스펙과 비교하여 추후 활용 가능.
세분화 요소라고 생각되어 Run name에 기입.
Run name - Model checkpoint name을 비교하여 확인하도록 세팅함.
-
Learning rate(DL)
Model checkpoint name의 epoch 대신 learning rate 기록.
세분화 요소라고 생각되어 Run name에 기입.
Run name - Model checkpoint name을 비교할 때 어차피 best checkpoint를 저장하고 early stop을 보통 사용하므로 max epoch를 기록할 필요 없음.
위 디테일 외 학습에 가장 큰 영향을 미치는 요소 중 하나인 learning rate를 선택.
-
Used Features(ML)
ML의 경우, 정형 데이터에서 feature selection을 하기 때문.
WandB Overview Config
이전의 경우, 이 기능 자체를 몰라서 기록하지 않아서 정확한 log 확인이 어려웠다.
기본 Project name, Run name에 여러 이유로 포함되지 않은 모든 요소들을 여기에 기록하도록 했다.
기존의 요소들도 물론 포함해서 비교할 수 있도록 하였으며, 사실상 main.yaml의 거의 모든 요소를 기록하도록 했다.
DL 예시
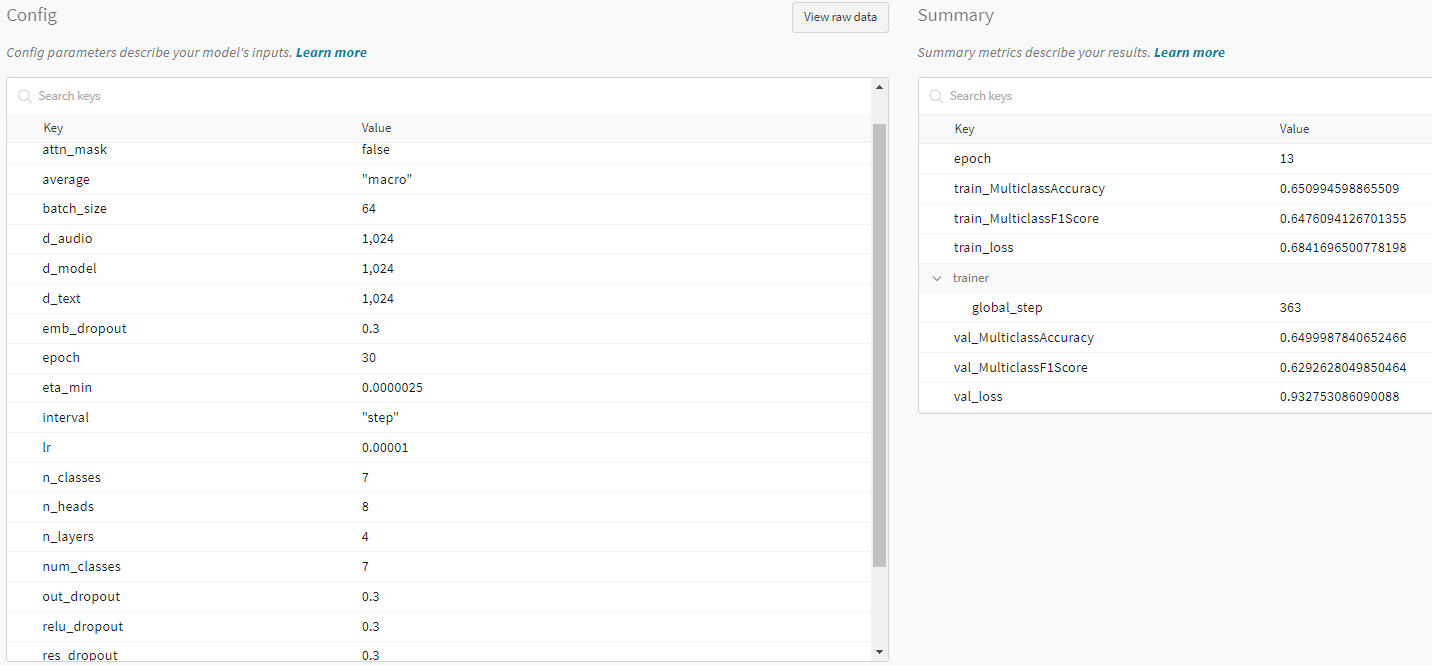
ML 예시
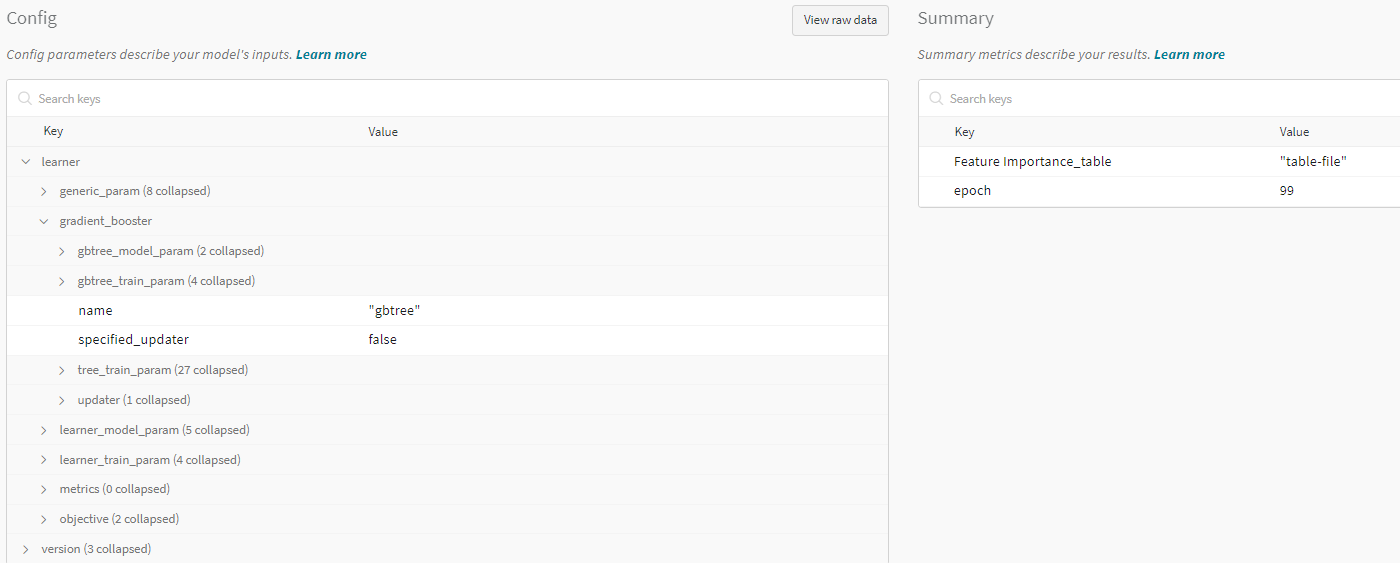
포함 요소
-
기존 요소들
Project name, Run name에 들어가는 모든 요소들.
기본적으로 overview config에서 최종 성능을 포함해 모든 요소들을 한번에 볼 수 있게 하기 위함.
-
Project, Run name에 포함되지 않은 모델의 hyper-parameters
Float type이거나 기타 이유로 logging name에 들어가기 힘든 hyper-parameters.
Dropout rate 등.
-
Project, Run name에 포함되지 않은 학습 관련 hyper-parameters
Float type이거나 기타 이유로 logging name에 들어가기 힘든 hyper-parameters.
CosineAnnealingLR Scheduler의 t_max, eta_min 등.
-
ETC
Dataset, Metric의 parameters를 포함한 기타 모든 parameters.
기타 수정 사항
Train, Test, Predict 뿐만 아니라, Tuning(hyper-parameters)도 WandB에 기록되게 했다.
Slack과 연동 및 wandb.alert() 기능을 이용하여 알람을 통해 확인할 수 있도록 기능을 추가했다.

후기
리팩토링과 업데이트는 하고자하면 끝이 없다.
발전하고자 할 수록, 더욱 더 자세히 알 필요가 있고, 깊이 고민할 필요가 있다.
댓글남기기