Transformer architecture and Depthwise separable convolution
Transformer architecture and Depthwise separable convolution
필요 및 공부 겸 META의 ConvNext 공식 구현 코드를 살펴보다가 갑자기 번뜩였다.
아! Transformer의 attention - feed forward는 Depthwise seperable convolution의 depthwise convolution - 1x1 pointwise convolution이랑 근원적으로 같구나!
Attention의 원리에 가려진 feed forward 또한 embed dimension의 확장과 축소를 통해 정보의 복잡한 변환을 학습하도록 설계된 중요한 부분이구나!
유레카까지 생각의 발전
ConvNext와 Attention is all you need 논문을 읽지 않은 것도 아니고, 직접 구현도 해보고 꾸준히 써왔는데 공식 코드 구현의 한 주석 때문에 번뜩였다.
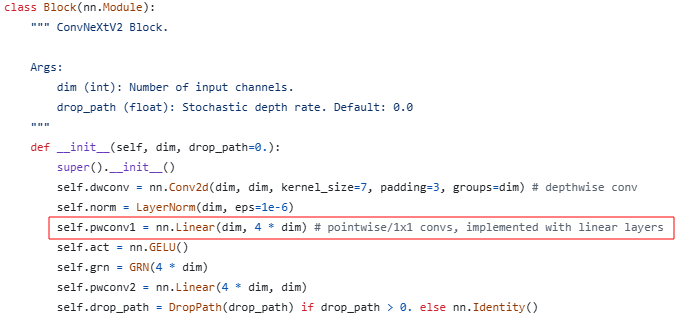
1x1 point wise convolution = linear
1x1 point wise convolution은 생각해보면 linear와 같다.
1x1 convolution filter를 1 in channel의 feature 전체에 걸쳐 연산을 수행한다.
이렇게 모든 in_channels 수 만큼의 in_channels에 대해 수행하여 1 out_channel을 생성하고, out_channels만큼 반복한다.
이건 결국 nn.Linear(in_features=in_channels, out_features=out_channels)와 같은 꼴이다.
이렇게 되면 ConvNext architecture의 다음 부분은 Transformer의 feed forward와 같다.
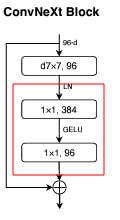
1x1 point wise convolution은 단순히 연산 효율성 뿐만 아니라 ConvNext block처럼 feature dimension을 늘렸다 줄이는식으로 두번 반복하면 channel의 확장과 축소를 통해 정보의 복잡한 변환을 학습하는 중요한 역할을 하며, 이것을 feed forwar에서도 마찬가지다.
depth wise convolution ≈ multi head attention
그렇다면 convnext layer의 앞의 depth wise convolution은 attention 연산과 비슷하지 않을까?
기본적으로 convolution과 attention 연산은 상호보완적이다.
또한, linear로 convolution을 구현할 수도 있고, convolution으로 attention을 구현할 수도 있다.
일반적으로 conv nd은 인접한 feature간 n dimension의 정보를 포함한 연산으로 새로운 feature를 생성한다.
attention은 전체 sequence length에서 각 token의 dimension간 연산을 통해 연관성을 찾아낸다.
ViT의 경우 linear attention으로 convnet을 대체하여 큰 공헌을 했지만, 여전히 수가 많지 않은 이미지 데이터셋에서는 locality의 특성을 잘 잡아내지 못하여, ConvNext, CVT 등의 convolution을 다시 활용한 모델이 등장했다.
Depth wise convolution을 보자.
Depth wise convolution은 groups를 in_channels만큼 최대로 나눠서 연산량을 효율적으로 줄인 convolution이다.
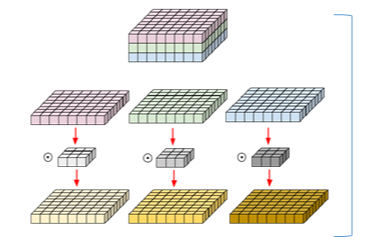
하지만 이렇게 보면 이 group이 multi-head와 닮아있다.
기존과 달리 1개의 filter가 1개의 in_channels만 담당하는 모습이 마치 head같다.
유레카
이렇게 보니 ConvNext block은 이렇게 해석할 수 있을 것 같다.
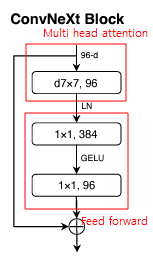
Normalization과 residual 연산 역시 상통한다.
당연한 말이지만, Transformer의 feed-forward도 매우 중요한 부분임을 되새긴다.
그리고 Meta 연구진들이 ViT와 비교하기 위해 같은 파라미터 사이즈로 실험했다고 했는데, 이런 식으로 설계했구나!
회고
예전에 공부할때는 Multi-head attention 연산의 의미에만 집중했었다.
또한, ConvNext에서도 Meta 연구진의 ViT와 같은 파라미터 상에서 성능을 비교했다고 했을 때 역시 깊이 곱씹어보지 않았다.
Stage 수와 STEM을 같게하고 block을 잘 설계하는 것만으로 parameter 사이즈를 맞추는 것이 생각해보면 쉽지 않은 일이다.
그리고 7x7 size filter가 단순히 high receptive field 때문에 썼다는 것을 받아들였지만, 생각해보면 3x3 conv를 여러 layer에 걸쳐 쌓는 것이 parameter size나 receptive field 면에서도 이득이다.
연구진이 이와 같이 설계한 것은 내가 유레카를 외친 원리를 이미 알고 있었고, Depth wise separable convolution을 조금만 변형하면 multi-head attention + feed forward와 다를 바 없다는 것을 이용하기 위함이었을 것이다.
모든 연구에는 해당 결과물이 나올 때 까지의 깊은 이해와 고민이 필요하다.
항상 다시 보고, 즐겨 보며, 되돌아보면서 음미하는 습관을 가져야겠다.
댓글남기기