머신러닝을 위한 EDA? EDA를 위한 머신러닝!
Upstage AI Lab 교육 EDA 프로젝트
👉🏻프로젝트 깃허브
현재 수강 중인 Upstage AI Lab의 EDA 교육 후 첫번째 EDA 팀 프로젝트에서 의료/바이오 분야를 선택, 머신러닝의 변수 별 중요도를 이용한 EDA 결과 검증 파트를 맡았다.
의료/바이오 분야는 아무래도 학부 전공, 그리고 대학원에서 적용한 데이터가 생리 신호이다보니 금융, 게임 등 다양한 분야가 있었지만 자연스럽게 관심이 갔다.
2조에 배정되었고, 1차 피어세션에서 같이 이야기 나누었던 팀원도 있어서 반가웠고, 비록 프로그래밍 지식은 부족할지라도 바이오 관련 전공으로 도메인 지식을 꽉잡고 있으신 분이 전체적인 방향을 리딩해주셔서 든든했다.
이런 교육 과정 등에서 처음으로 팀 프로젝트에서 리드를 하는 것이 아니라 리드를 당해서 좋았다(?).
보통은 모두가 빼면 팀장을 맡는 성격이지만, 학위논문 최종 수정 및 제출을 앞두고 있어서 도저히 팀장까지는 맡을 수 없었다.
데이터셋의 선정에 있어서 팀 차원에서 많은 고민이 있었다.
의료/바이오 데이터셋의 최대 문제점은 환자의 개인정보가 들어간다는 것이다.
그래서 자세한 정보가 기록된 데이터는 절대량이 작고, 절대량이 많은 데이터셋은 자세한 생체 지표 및 개인 정보가 없는 trade-off 관계가 있었다.
하긴 학위 연구에서도 모두 직접 실험한 데이터 혹은 학술용으로 오픈되어 따로 신청해야하는 데이터셋들만 사용했지, 오픈 데이터셋은 찾아볼 수 없었다.
그래서 내린 결론은, 어쨌든 EDA 프로젝트 목적에 맞춰서 적은 데이터셋보다 비록 정보가 떨어질지라도 절대량이 많은 데이터셋을 선정 후 그 안에서 EDA를 통해 유의미한 정보들을 찾는 방향으로 가는 것이었다.
그래서 선택한 EDA 데이터셋은 Kaggle의 당뇨병 데이터셋이다.
👉🏻데이터셋
해당 데이터셋은 순수히 생체 정보를 담기보다 미국 CDC에서 설문조사를 통해 고혈압, 고콜레스테롤, 나이, 성별, 소득 정도, 헬스케어 유무 등을 정보로 기록하고, 당뇨 / 비당뇨를 binary labels로 기록한 데이터셋이다.
데이터셋 선정 이유
- 질병을 주제로 데이터셋을 검색 중 당뇨병 관련 오픈 데이터셋이 가장 많음
- 기간 내에 빠르게 구할 수 있는 데이터셋 중에 양이 가장 많음
데이터셋의 장점
- Kaggle 등의 당뇨병 관련 오픈 데이터셋 중에 양이 가장 많음
- 결측값이 적은 편임
- 전처리하기 쉬운 tabular dataset이 파일별로 나눠져있음
- 어중간한 당뇨 정도를 통일하여 binary labels로 만든 데이터셋, 클래스 불균형을 고려하여 major label은 undersampling한 데이터셋이 존재함
데이터셋의 단점
- 대부분의 feature들이 0 혹은 1의 binary categories임
- 그 외 feature들도 충분히 numeric features로 기록할 수 있는걸 다시 mutilcasses로 카테고리화하여 기록됨(raw numeric values에 대한 정보 없음)
- 당뇨 9 : 비당뇨 1 정도의 class imbalance 존재
위와 같은 단점에도 불구하고, 관련 전공자도 팀 내에 존재하여 최대한 reference backup을 통해 사전 지식 기반으로 가설을 세우고 EDA를 진행했다.
머신러닝을 통한 EDA 결론 검증
초기에는 팀 내에서 EDA 방향을 위한 가설 설정에 참여했고, 후에 내가 맡은 주된 파트는 머신러닝을 통한 EDA 결론 검증이다.
EDA를 통해 도출한 중요 변수들이 과연 머신러닝 학습에서도 중요하게 작용할지, 성능 최적화된 모델의 feature importance를 통해 확인하는 것이다.
주요 라이브러리
python>=3.8
hydra-core
lightgbm
matplotlib
numpy
omegaconf
openpyxl
optuna
pandas
scikit-learn
scipy
tqdm
wandb
xgboost
역할을 맡게 된 계기
- 애초에 데이터셋 자체가 머신러닝을 이용한 분류를 위한 목적이 큼
- 초기 피드백 때 머신러닝을 어느 정도 이용하는게 좋겠다는 피드백을 받음
- 팀 내 유일 머신러닝 경험자(프로젝트에서 실질적 사용 및 최적화 경험)
- 학위 연구에서 사용된 머신러닝 프로젝트를 평소 사용하던 pytorch-lightning, hydra, wandb를 이용한 딥러닝 프로젝트 구조에 맞춰 리팩토링을 진행하던 김에 같이 진행함
역할 상세 및 과정
머신러닝 프로젝트였다면 EDA 결과를 바탕으로 머신러닝을 진행하고 최적화했겠지만, 이번 프로젝트의 주제는 EDA였다.
따라서, 내가 독자적으로 성능 최적화된 머신러닝 모델을 완성하여 해당 모델의 변수 별 중요도가 EDA 결과와 상응하는지 확인하는 방향으로 진행했다.
데이터 전처리
데이터 전처리는 최대한 기본만 적용했다.
데이터 자체가 null 값이 많은 것도 아니고, 대부분이 binary categoris라 처리할 것이 많이 없었다.
또한 당뇨병과 정말 상관성이 없는 변수들이 있는 것도 아니라 보든 변수들을 포함시키는 것이 모델의 성능을 조금이라도 더 향상시켜주었다.
트리 기반 모델을 사용하여 다중공선성 문제도 어느 정도 해결이 됐다.
그리고, 모든 변수를 활용한 머신러닝 모델의 feature importance에서 EDA 결론의 변수들이 상위에 랭크되어 있다면 EDA 결론을 잘 뒷받침해주기 때문이다.
모델 학습
LightGBM, XGBoost의 기본 classifier로 모든 변수를 학습시키는 방식으로 진행했다.
초기에는 정확도가 0.88 정도 나왔으나, f1 score가 0.2 미만으로, 모델이 major class인 비당뇨(0)으로 추론하는 과적합 양상을 보였다.
이후, wandb sweep과 optuna를 이용해 하이퍼 파라미터 최적화를 진행했고, 반복 실험 관리는 hydra-core로, logging은 wandb로 진행했다.
(실험 logging 중 일부, 10 fold 학습 진행의 흔적)
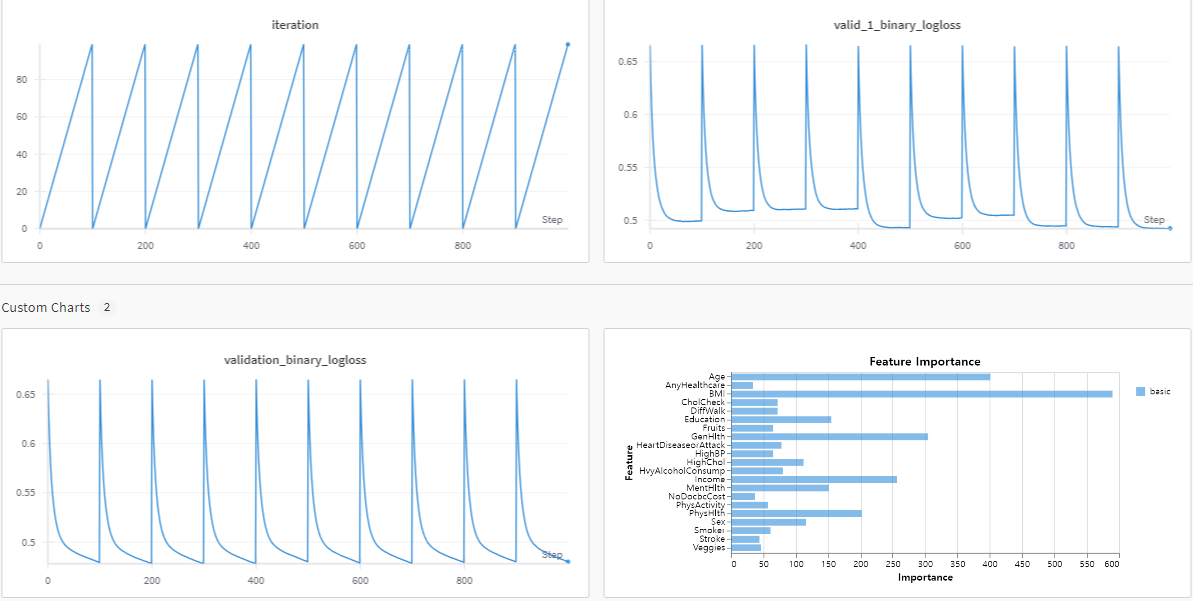
결론
머신러닝 모델의 성능 자체는 좋았다.
최종 모델은 XGBoostClassifier를 optuna를 통해 최적화된 모델이었다(100회 서치를 하는데 두시간 정도 걸렸다).
최종 정확도 0.96, f1 score 0.96을 달성했다.
(프로젝트 발표 슬라이드 중 모델 성능 파트 캡처)

그러나 총 EDA를 통한 가설 검증으로 얻은 9개의 변수 중에 4개만 상위에 랭크되었고, 5개는 중요도가 매우 낮았다.
4개 중 3개(BMI, Age, Income)은 1~3위였으나, 이들은 binary categories가 아닌 multi-categories 혹은 numeric features였다.
EDA 결론과 상충되는 5개의 변수는 모두 binary categories였다.
EDA 결과에는 없지만 feature importance 상위에 랭크된 변수들도 있었는데, 대부분 multi-categories였다.
(프로젝트 발표 슬라이드 중 변수 별 중요도 파트 캡처)

위의 결과를 바탕으로 아래와 같은 결론을 내렸다.
-
binary categories가 너무 많아서 데이터의 의미보다 데이터의 형태(binary categoris가 아닌 변수들이 feature importance 상위에 랭크)가 모델 학습에 더 영향을 미쳤음.
-
만약 설문조사에서 내용을 모두 세세하게 받았다면, 단순 당뇨/비당뇨 클래스 구분 성능 향상 뿐만아니라, 클래스가 당뇨 단계별로 세분화되어 기록되어 있을지라도 준수한 성능을 달성했을거라 예상함
후기
약 1주일 정도의 짧은 프로젝트 기간이 있었지만 팀 프로젝트로 다양한 사람들과 같이 할 수 있어서 재밌었다.
졸업 논문 수정, 학위 연구의 머신러닝 프로젝트 리팩토링과 같이 진행하느라 바빴지만, 토의하고 실험하는 과정 자체가 즐거웠다.
데이터의 양도 양이지만, 의미 있는 결론을 도출하기 위해서는 역시 데이터의 질이 중요하다.
딥러닝 프로젝트를 구조화하고나서 머신러닝 프로젝트도 pytorch-lightning 모듈 부분을 일반 클래스로 대체하여 그 안에서 dataloader, trainer를 직접 구현해도 괜찮다는 생각을 했었는데, 이 기회에 진행하니 속 시원했고, 구조에 대해 고민하는 재미도 있었다.
구현 및 리팩토링을 진행하면서 추가로 알게 된 기능과 라이브러리 등이 있었던 만큼, 더 쓸만한 구조들을 앞으로 발견할 확률이 높다(추가 리팩토링의 가능성은 항상 열려있다).
댓글남기기