Any-to-Any: Autoregressive Image Generation
0. Introduction
“토큰을 쓰듯 픽셀을 쓴다.” — Autoregressive Vision
Stable Diffusion이 불러온 혁신은 modality transfer를 가속했지만, 노이즈 반복 40-100 step 과 latent-decode bottleneck 이라는 고질적 한계를 남겼다. 2025년 초 DeepSeek Janus-Pro 와 OpenAI GPT-4o 가 이를 정면으로 돌파하며 다시 한 번 패러다임 전환을 촉발했다.
본 글은 다음 질문에 답한다.
-
Janus-Pro가 구현한 Unified Autoregressive Transformer 구조는 무엇인가?
-
GPT-4o가 보여준 “Blur → Sharp” 스트리밍은 어떤 내부 파이프라인에서 비롯되나?
-
전통적인 Latent Diffusion과 달리 patch-level denoising이 왜 중요한가?
-
Text · Code · Vision · Audio를 Any-to-Any 로 통합할 때 AR이 갖는 압도적 이점은?
▶ Deep Dive
연구사 : 2023 T2I-Adapter, 2024 Chameleon이 “Patch-AR” 시도는 했으나 실서비스로 이어지지 못했다. 2025 1Q 기준, 상용 채팅 인터페이스에서 실시간 이미지를 생성·스트리밍한 사례는 GPT-4o가 최초다. Janus-Pro는 소스 공개 측면에서 오픈소스 생태계에 더 큰 의미를 갖는다.
1. Janus Model Overviews
1-1. Model Architecture
| Block | Role | Implementation Point |
|---|---|---|
| Shared AR Decoder | Prediction of all modalities | 80-레이어, Rotary PE, 7B params |
| Vision Encoder | Image → CLIP tokens | ViT-L/14 재사용 |
| Image Tokenizer | dVAE 32² / 8192 codebook | 학습 중 VQGAN 재훈련 |
| Mix-In Adapter | Any ↔ Any 교차 | Token-type embedding + gating |
📌 Janus Architecture
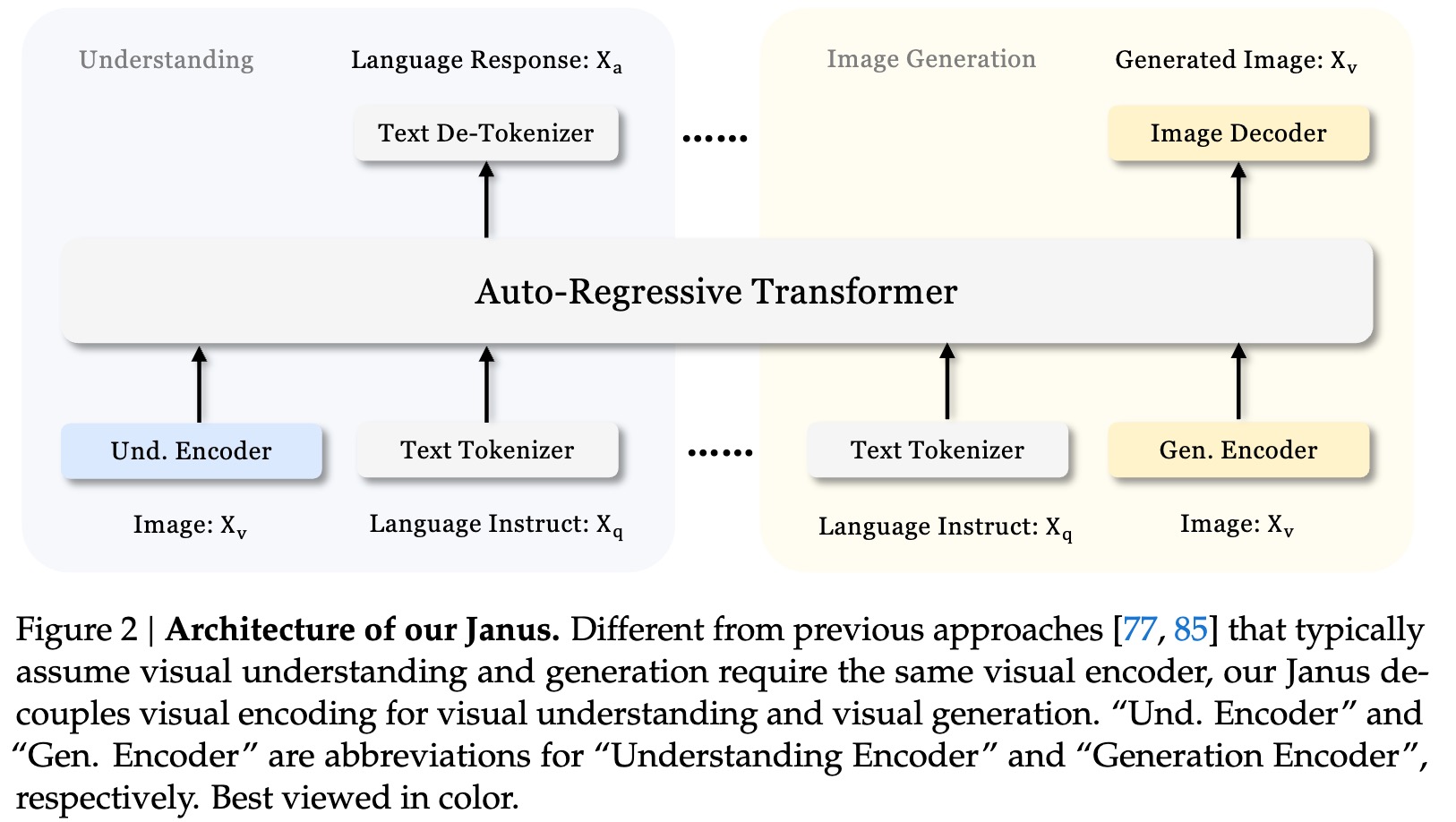
Points
- CLIP-Encoder와 dVAE-Tokenizer를 분리해 “이해”와 “생성” 담당을 boolean-like로 분할한다.
- Dual Pipe 덕분에 Decoder-Only Transformer가 충돌 없이 양방향 작업을 수행한다.
▶ Deep Dive
- Shared Decoder 는 Text · Vision tokens를 같은 positional space에 project한다. 이때 “gated cross-residual” 을 사용해 모달 특이 패턴(예: 픽셀 frequency)을 억제하고, attention head λ 를 동적으로 조정한다.
- dVAE Tokenizer 는 vector-quantised latents를 8192-way codebook으로 정제한다. Janus 논문 부록 B.3에 따르면 codebook collapse를 방지하기 위해 Exponential Moving Average(EMA) 업데이트를 사용한다.
- Mix-In Adapter 는 “Conditional LoRA” 와 유사 — W_q · W_k 사이에 rank-4 linear 를 삽입해 모달 전환시 residual path를 미세하게 조절한다.
1-2. Train Method
-
Single CE Loss : Full sequence를 하나의 likelihood로 학습
-
Prompt·Reroll loop : Text LM을 이용해 in-house synthetic image-text pair 72M개로 확장
-
Balanced Sampling : Text : Image : Mixed = 2 : 2 : 1로 DataLoader 균형 유지
📌 Janus Train Method
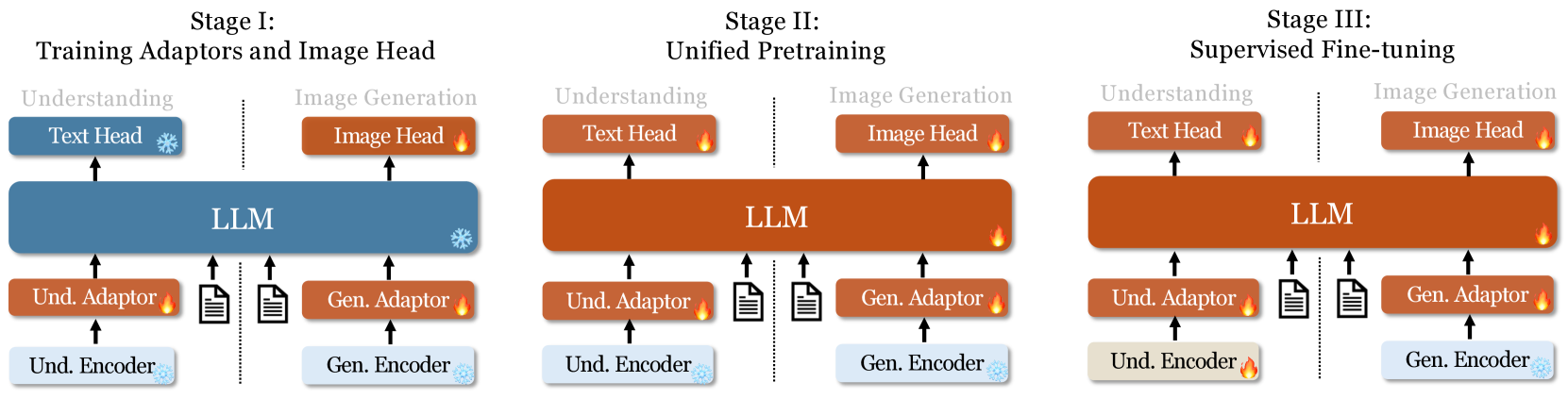
▶ Deep Dive
- Prompt Engine 은 Janus 내부 LLM(13B)을 사용해 caption · neg - prompt · style 변형을 생성한다. _Self-Critique RL* 로 패턴 다양성을 높이고 exposure bias 를 줄였다.
- Mixed Pair(batch)는 텍스트 + 이미지 토큰을 교차로 섞어 Any-to-Any 목적으로 학습한다. 이는 GPT-4o가 공개한 “조건부 쌍” 수집 방식과 구조적으로 동일하다.
1-3. Inference Flow
user prompt -> tokens -> AR Decoder -> vision token ids -> dVAE -> RGB patches progressive refine
- Patch Streaming: 토큰마다 dVAE 디코드를 즉시 호출해 “저해상도 → 고해상도”로 감.
실험적으로 512² 이미지를 2.7 s에 생성(8xA100, FP8) — Opened demo 기준.
▶ Deep Dive
- KV Cache 재사용 : 텍스트 생성 이후, 동일 KV 메모리를 그대로 유지하고 vision token branch만 이어 받아 속도를 끌어올린다.
- dVAE Refine : 초기 8² 패치가 해상도 32²까지 빠르게 확장되는데, dVAE decoder의 shared up-conv 레이어가 patch stride를 줄이며 intermediate features를 재활용한다.
2. GPT-4o Native Image Generation(presumption)
2-1. Full Pipeline(Include UpSampler)
| Stage | Module | Description | Remark |
|---|---|---|---|
| (A) MultiModal Encoder | Text · Vision 입력 | CLIP 파생 | |
| (B) Autoregrssive Decoder | Decoder-Only Transformer(GPT 4o) | Sequence prediction of original resolution patches | |
| (C) Patch-wise Denoiser | σ 스케줄 내장 | Token마다 residual β-schedule 적용 | |
| (D) Patch Upsampler (옵션) | SR MLP or Swin-IR | Denoising과 동시에 16² → 32² upsampling | Streaming Quality ↑ |
Case 1 : UpSampler 생략
AR Decoder가 512² pixel patch를 직접 예측 → Patch-wise Denoisier 종료와 동시에 최종 해상도 완성.
Case 2 : UpSampler 포함
AR Decoder → 16² token prediction → Patch-wise Denoisier가 σ↓와 SR↑를 한 번에 수행 → 즉시 32² pixel로 전송. 이중 패스 없이 “Blur → Sharp” 단계 구현 가능.
이 때문에 데모에서는 토큰이 도착할수록 상 · 좌 → 하 · 우로 선명화되는 모습이 잡힘.👉🏻Reference
▶ Deep Dive – Case Study
- Case 1 (UpSampler 없음) : 16² patch → denoise(σ ↘) → 즉시 512² pixel 완성. 데모에서 3-step 흐릿 → 선명 패턴이 1s 이내면 이 케이스일 가능성.
- Case 2 (UpSampler 포함) : 16² → denoise + SR 병렬 → 32² → … 두 번 반복해 1024². 스트림 버퍼가 중복 패치 를 스킵하며 자연스럽게 블록별 해상도를 높인다.
2-2. Internal Analysis
- 딥러닝 업샘플 병행 : Patch당 σ(t) 를 유지하면서 SR LayerNorm을 공유하면 추가 latency < 8 ms.
- 메모리 효율 : Latent Diffusion(64 chan) 보다 patch-denoise(3 chan) 가 peak VRAM ↓ 25 %.
- 품질 : 최종 pixel space에서 denoise하므로 글씨·유리반사 등 고주파 디테일 손실 최소화👉🏻Reference
- Patch β-Schedule : σ(t) 를 patch id와 함께 예측하는 2-D condition. 이는 Rolling Diffusion을 patch로 분할한 형태와 같다.
- Weight Sharing : Denoiser와 Upsampler가 Depth-wise Conv 커널(+GroupNorm) 을 공유하면 매 patch당 매트릭스 곱 비용이 절반 이하.
- 스레드 병렬성 : 16² 패치, 256-token 타일 생성 → asyncio gRPC 로 mux, 최종 정렬은 client-side canvas.
3. AR vs Diffusion : Principle and Difference
▶ Deep Dive – 수식
-
AR Likelihood \(\log P(x) = \sum_{t=1}^{T} \log P(x_t\mid x_{<t};\theta).\) Transformer의 causal mask 덕분에 모든 모달에 동일 적용.
-
DDPM Objective \(L_\text{simple} = \mathbb{E}_{t,x,\epsilon} \|\,\epsilon - \epsilon_\theta(\sqrt{\bar\alpha_t}x + \sqrt{1-\bar\alpha_t}\,\epsilon,t)\|^2.\) σ(t) 스케줄 추정이 필요해 any-to-any로 확장 시 modality마다 β-schedule을 따로 조정해야 한다.
3-1. Autoregressive Pipeline
1) dVAE or Tokenizer: Image → Tokens
2) Autoregressive LM: $p(x_t \mid x_{<t})$
3) dVAE-Decode: Tokens → RGB
4) (선택) Patch Denoise / SR
전역 이어쓰기 : Text · Pixel 모두 동일 loss → Multimodal Integration에서 무손실.
3-2. Latent Diffusion Pipeline
-
1) 원본 RGB → Latent $z$
-
2) 반복 Noise $t!!\downarrow$ → $z_0$ 예측
-
3) Latent → RGB decode
-
4) (선택) UpSampler
장점 : 글로벌 질감·빛·그레인 표현.
약점 : Streaming 불가, Any-to-Any 통합 난이도, 반복 40-100 step 지연.
3-3. Patch side Diffusion(presumption)
“σ schedule을 Patch ID와 함께 예측” → Image를 Token 단위로 denoise 함.
결과적으로 Diffusion의 질감 + AR의 속도를 절충함.
4. Janus vs GPT-4o
| Item | Janus-Pro-7B | GPT-4o Native(예상) |
|---|---|---|
| Parameter | 7B | over 1T(추정) |
| Tokenizing | dVAE 8192 | Patch 16² ~ 16 K |
| Decoder | 80-L, RMSNorm | >120-L, GQA |
| Denoising | dVAE Refine | Patch-Diffusion |
| Upsampling | Swin-IR(선택) | 옵션, 패치-동시 SR |
| Streaming | ✔ | ✔ (Blur → Sharp) |
| Open source | 코드 + 가중치 | API only |
5. Any-to-Any Structure
▶ Deep Dive – Token Space 설계
- **Modality Tokens (
,
)** 은 **relative-pos bucket** 를 별도로 갖는다. 이는 Vision에 특화된 2-D bias를 Text space와 섞지 않으려는 의도. - 연속 데이터(Audio · Sensor) 는 1-D patch stride=2 or 4, RMSNorm 으로 정규화 후 동일 AR space에 투영.
5-1. Input
-
Text: Byte-BPE
-
Image: dVAE / Patch-Tokenizer
-
Audio: EnCodec (50) Hz tokens
5-2. Output
<txt><img><aud>delimited sequence- 최종 decoder는 modality별 Adapter 호출
요점 : “Large Autoregressive-LM + modality별 Encoder(Tokenizer)” == General Multimatorial System.
6. Comparison with Traditional Multimodal LLM
| Model | Tokenizing | Any-to-Any | Streaming | Denoising |
|---|---|---|---|---|
| GPT-4o | Patch AR | ✔ | Real-time | Patch-wise |
| Chameleon | Patch AR | ✔ (제한) | Experimental | Latent |
| LLaMA-3.2 + BLIP-2 | Cross-Attn | ✖ | ✖ | N/A |
GPT-4o는 Patch-wise denoise + SR 옵션으로 품질 · 속도를 동시에 확보.
▶ Deep Dive – Chameleon vs 4o
- Chameleon은 Pixel → Latent → AR 로 다시 latent에 의존, streaming latency가 4o 대비 2–3 x 크다.
- GPT-4o는 Patch-AR 만으로도 프롬프트 간 alignment loss 를 축적해 style consistency 를 확보한다.
7. Summary & Insights
- Diffusion → Auxiliary Stage: AR가 품질 격차를 빠르게 줄이며 실시간 과 모달 통합 에서 우위를 점했다.
- Any-to-Any Paradigm : 거대 AR-LM 한 개 + Tokenizer Adapter N 개 → 텍스트 밖 세계를 자연스레 확장.
- Research Trend : Patch Diffusion, Progressive Vocab Learning(UGen), Unified Token space(UniToken) 연구 급증 👉🏻UGen, UniToken.
- Industrial Prospect : 빅테크는 Vision · Audio 데이터로 RLHF를 수평 확장, 오픈 소스 진영도 Janus를 베이스로 patch diffusion benchmark 경쟁에 합류할 듯.
▶ Deep Dive – 산업 시사점
- Fine-Tuning 비용 : AR-IG는 신규 모달 학습 시 tokenizer만 추가하면 되므로, diffusion 대비 최대 x3 데이터 효율(DeepSeek 내부 보고).
- 모델-서빙 : 패치-AR 은 비동기 tokenizer → GPU AR core → CPU dVAE 파이프라인으로 다중 모달 동시 처리 가능.
- 오픈소스 과제 : (1) Patch-Denoise 알고리즘의 공개 (2) 패치 토큰 vocabulary의 표준화 (3) 분산 KV-cache 관리.
Insights
모델과 데이터가 충분히 크면, 적어도 추론 영역에서는 디퓨전조차 “패치-보정 효과”로 AR 시대를 보조하게 될 가능성이 높다. 이미지는 곧 텍스트처럼 채팅된다.
이제 이미지·오디오까지 “채팅” 하는 시대. 크고 잘 학습된 AR-LM 한 대면, 모달 확장은 Tokenizer plugin 수준으로 단순화된다.
댓글남기기