DP와 DDP에 대해 정리하고 넘어가자
DataParallel, DistributedDataParallel
DataParallel(이하 DP)와 DistributedDataParallel(이하 DDP), multi-GPU를 사용해본 사람이라면 무조건 들어봤을 것이다.
연구실에 들어와 처음 서버를 신청하고 할당받은게 윈도우였을 때의 그 답답함… 아직도 기억이 생생하다.
multi-GPU지만, NCCL backend가 linux에서만 지원해서 결국 DDP가 아닌 DP를 사용할 수 밖에 없었고, all-reduce 연산이 아닌 rank 0의 GPU가 과중한 일을 부담함으로써 생기는 GPU 별 사용률 문제, batch size를 full로 땡길 수 없는 문제, LightningModule에서 log에 관한 옵션 설정 등에 대해 고생했던 기억이 있다.
그렇다면 공식 가이드, 커뮤니티 등에서 모두 DP 대신 DDP를 권장하는 이유가 무엇일까?
왜 DP가 DDP에 비해 비효율적인지, DP에서 DDP로 전환할 때 주의할 점들을 알아보자.
DP(DataParallel)
사전 정보
- DP는 single node, multi-GPU에서 동작하는 multi-thread module이다.
- rank 0의 GPU에 계산 결과를 모으고 다시 broadcast하기 때문에 rank 0 GPU로의 가중이 심하다.
- Python은 GIL(Global Interpreter Lock)로 인해 1개의 프로세스에서 다중 쓰레드가 동작할 수 없어서, multi-thread는 비효율적이다.
Forward Pass
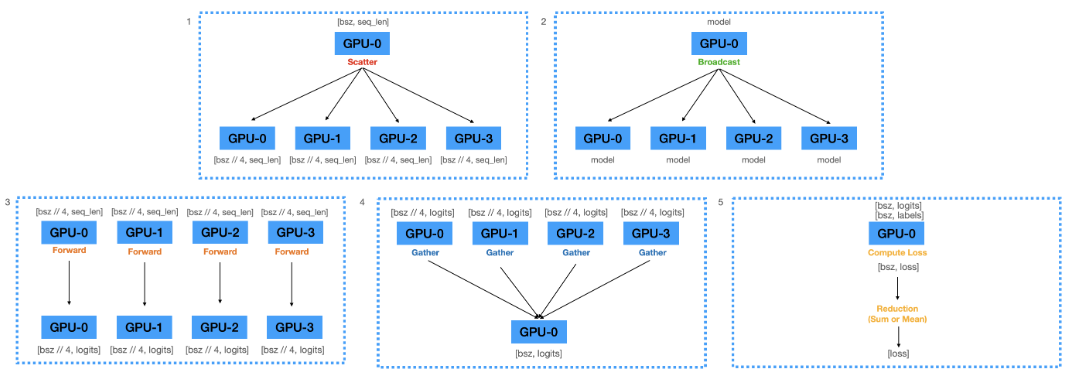
- main GPU에서 batch를 각 GPU로 분할__(Scatter)__.
- main GPU에 올려져있는 model parameters를 각 GPU로 복제__(Broascast)__.
- 각 GPU에 복제된 model에 batch를 입력하여 logits을 구함__(Forward)__.
- 각 GPU에서 계산된 logits을 main GPU로 모음(Gather).
- Gathered logits으로 Loss 연산.
Backward Pass
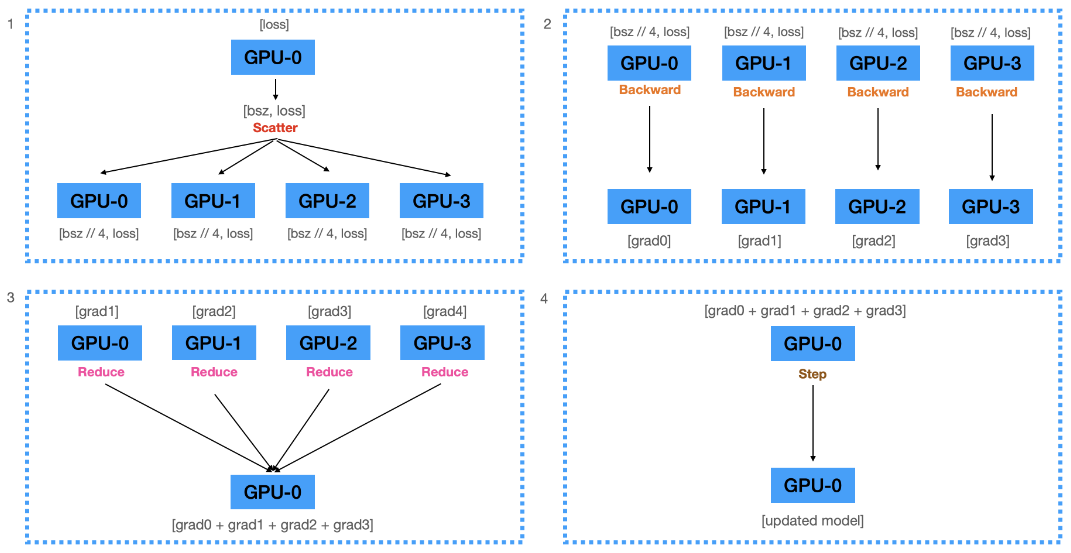
- main GPU에서 계산된 loss를 각 GPU에 전달(Scatter).
- 전달받은 loss를 통해 각 GPU에서 gradients 계산(Bacward).
- 각 GPU에서 계산된 gradients를 main GPU에 모아서 모두 더함(Reduce).
- main GPU에서 reduced gradients를 이용하여 model update.
위와 같은 방식은 main GPU에 logits이 쏠리기 때문에 GPU VRAM 사용 불균형 문제가 일어난다.
이와 같은 메모리 불균형 문제는 logits이 아닌, loss를 Gather하는 방식으로 변경하면 어느정도 완화 가능하며(loss는 scalar이기 때문에 logits에 비해 메모리 할당 사이즈가 훨씬 작음) 아래와 같은 도식으로 표현할 수 있다.
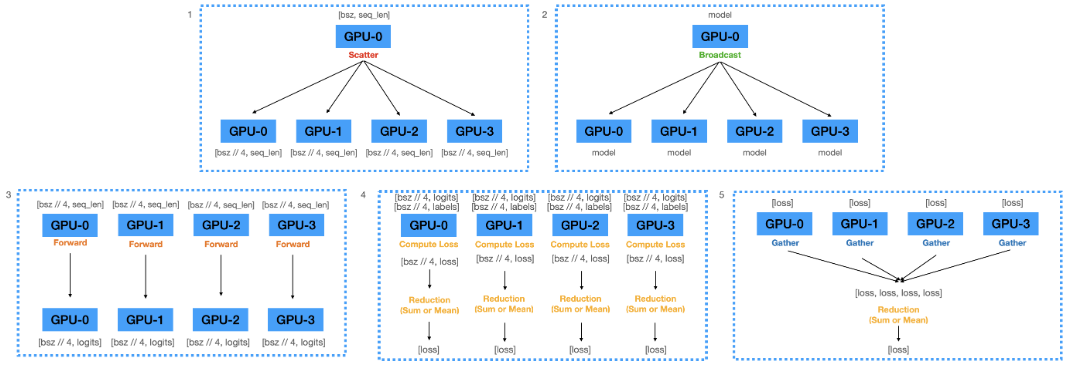
위와 같은 방식으로 구현한다면, 4번과 5번에서 알 수 있는 reduction이 2번 일어나게 된다. 그럼에도 불구하고, main GPU의 메모리 부담은 훨씬 적다.
DP의 문제점
-
Python에서 비효율적임
위의 사전 지식에서 알 수 있듯, multi-thread module은 Python의 GIL로 인해 비효율적이며, multi-process module로 구성하는 것이 근본적인 비효율 개선책이다.
-
매 step마다 main GPU에서 update된 model이 다른 GPU로 복제되어야 함
각 GPU에서 계산된 gradients를 main GPU로 모아서(Gather) update하고, updated model을 매 step마다 다른 GPU로 복제(Broadcast)해야 하는 비효율이 발생한다.
DDP(DistributedDataParallel)
DP의 비효율을 해결하기 위해 gathering gradients를 하지 않고, 각 GPU에서 자체적으로 step을 밟는다면 매 step마다 main GPU에서 다른 GPU로 updated model을 복제하지 않아도 된다.
그러면 어떻게 구현할까?
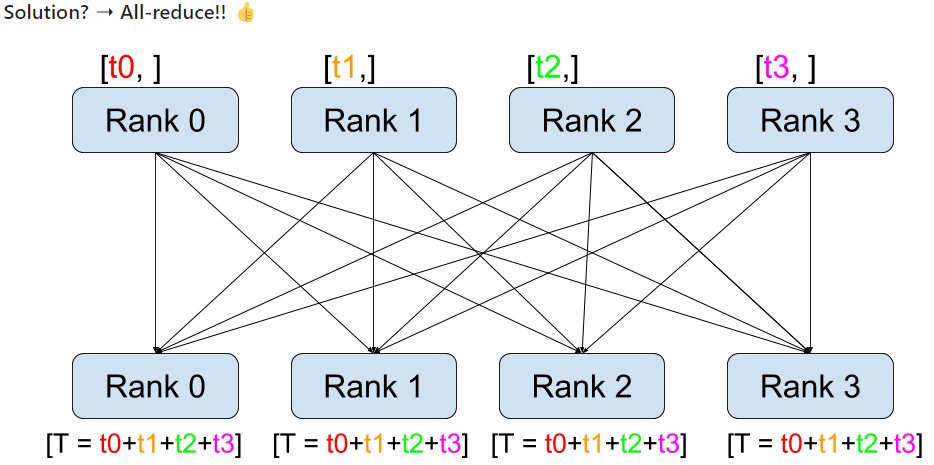
이런 식으로 all-reduce 연산을 통해 각 GPU에서 계산된 gradients를 모두 더해서 모든 GPU에 전달한다면 각 GPU에서 자체적으로 step을 밟을 수 있고, main GPU로 부터 updated model을 복제할 필요가 없다.
하지만 all-reduce 연산의 비용은 매우 비싸다.

먼저 DP의 연산 방식이다.
main GPU의 메모리 부하가 심하나, GPU 간의 통신 비용은 GPU 수에 비례한다.
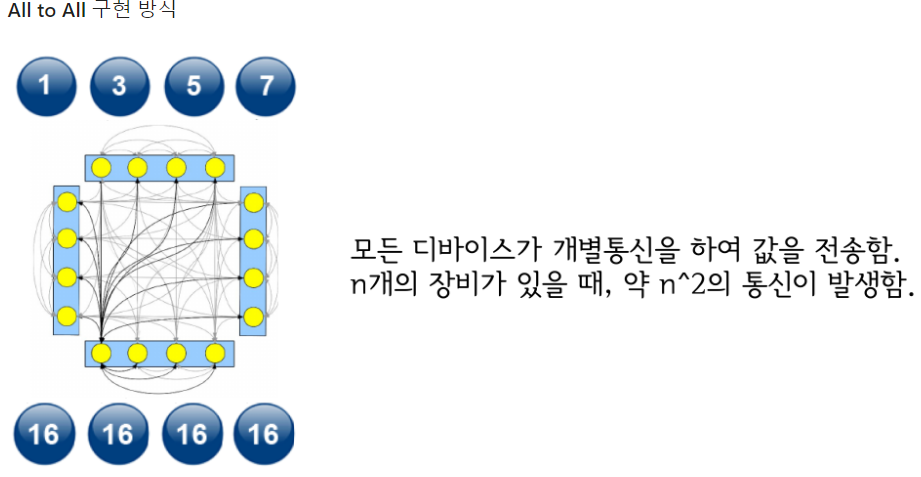
일반적으로 생각할 수 있는 all-to-all reduce 방식이다.
main GPU 없이, GPU간 균등한 메모리 부담을 가지나, GPU 간의 통신 비용은 GPU 수의 제곱에 비례한다.
통신 비용을 줄이기 위한 방법을 고안해야만한다.
Ring All-reduce
👉🏻Baidu ring all-reduce github
Ring All-reduce는 2017년에 Baidu의 연구진이 개발한 새로운 연산이다.
기존 방식들에 비해 월등히 효율적인 성능을 보여줬기 때문에 DDP 연산의 핵심이 되었다.

위와 같은 방식으로 다음과 같은 장점을 갖는다.
- main process를 사용하지 않기 때문에 특정 GPU로 메모리 부하가 쏠리지 않음.
- All-to-ALL처럼 비효율적으로 GPU간 통신 비용이 많이 들지 않음
- 모든 GPU의 model parameters를 동시에 update하기 때문에, 매번 updated model을 복제할 필요 없음.
그래서 DDP란?
DP의 문제를 개선하기 위한 데이터 병렬처리 모듈이며, single/multi-node & multi-GPU에서 동작하는 multi-process 모듈이다.
All-reduce를 활용하게 되면서 main process의 개념이 없어졌기 때문에 학습 과정이 매우 심플하다.
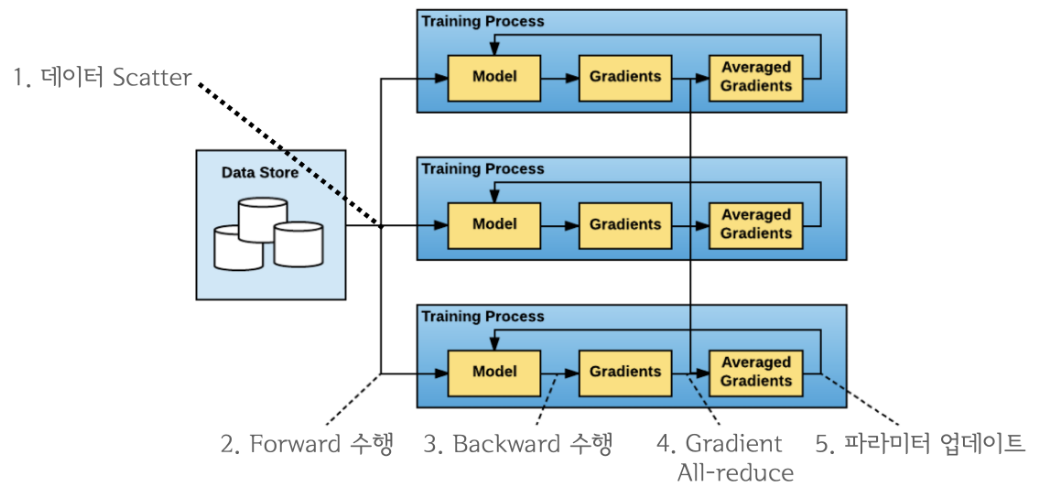
위 그림과 같이 매우 간단하게 연산을 처리할 수 있다.
그렇다면 언제 all-reduce 연산을 수행하는 것이 좋을까?
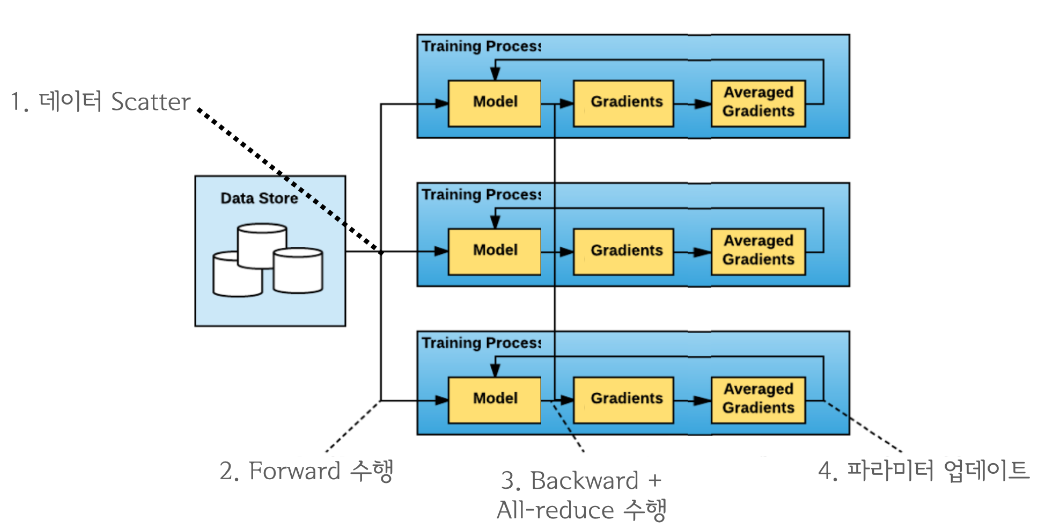
결과적으로 backward pass와 all-reduce를 중첩시키는 것이 가장 효율적이다.
all-reduce는 네트워크 통신, backward와 step 등은 GPU 연산이기 때문에 동시에 처리할 수 있기 때문이다.
Computation과 communication이 최대한으로 overlap 되도록 이들을 중첩시켜 연산 효율을 높인다.
DP에서 DDP로 넘어올 때 주의사항(batch size)
DP와 DDP의 차이에서 PyTorch-Lightning을 쓴다면, LightningModule의 log 옵션에서 DP나 DDP에 따라 sync_dist 혹은 rank_zero_only option을 다르게 설정해줘야할 것이다(참고 링크).
하지만 이것보다 더 신경써야할 것은 batch size다.
👉🏻DP와 DDP batch size 관련 질문 링크 1
👉🏻DP와 DDP batch size 관련 질문 링크 2
👉🏻DP와 DDP batch size 관련 질문 링크 3
역시 위 링크들과 같이 헷갈리는 주제인데, DataLoader에 batch_size를 입력할 때, DP와 DDP의 적용 방식이 다르다.
만약 GPU 4개인 node에 대해 DP or DDP를 수행할 때 batch_size=64로 준다면,
-
DDP의 경우 node 전체의 batch size는 64*4=256이다.
DDP는 main GPU 없이, multi-process로 실행된다. 즉, 각 process(GPU)마다 64의 batch size가 부여된다.
-
DP의 경우 node 전체의 batch size는 64다.
DP는 main GPU에서 batch를 scatter해주는 multi-thread 방식이다. 즉, 각 thread(GPU)가 전체 batch를 나누어 가지므로, node 전체의 batch size는 64, 각 GPU의 batch size는 64/4=16이 된다.
후기
이전에 DP에서 DDP로 넘어갈 때 한번 정리했어야 할 내용을 이제 정리한다.
그때는 어떻게는 윈도우즈 서버에서 DDP를 사용하겠다고 고군분투하다 지쳤어서 여력이 없었다.
이전에 겪었고, 지금 잘 사용하는 기능이라도 한번쯤은 되짚어보고 제대로 이해할 때 추가적인 발전이 있다.
댓글남기기