DeepSeek-R1 Review
DeepSeek-R1 Review
👉🏻논문 링크
👉🏻비주얼 가이드
DeepSeek‑R1은 DeepSeek-V3-Base를 기반으로 하는 Reasoning 모델이다. 기존 DeepSeek‑V3의 학습 파이프라인과는 달리, R1은 SFT 단계 이전에 “R1‑Zero”라는 순수 RL 기반 Reasoning 모델을 먼저 구축하고, 이후 소량의 Cold Start Data를 활용해 Interim Reasoning Model을 생성, 이후 대규모 RL을 거쳐 RL checkpoint를 만들고 RL checkpoint를 SFT rejection sampling에 활용 및 SFT 적용, 그리고 일반 RL 과정을 거쳐 최종 모델로 완성된다. 이번 리뷰에서는 DeepSeek‑R1의 핵심 아이디어와 전체 흐름, 그리고 전통적인 학습 파이프라인과의 차별점을 중심으로 살펴본다.
Training Pipeline
DeepSeek‑R1의 학습 파이프라인은 전통적인 LLM 학습 흐름(pre‑train → SFT → RL → Reasoning 모델)과 비교할 때 다음과 같은 차별점을 보인다.
- Traditional Train Pipeline (예: GPT‑o1)
- 일반적으로 Pre‑training으로 거대한 웹 데이터(> 10T tokens)를 활용한 후, Supervised Fine‑Tuning(SFT) 및 Preference Tuning(RL)을 진행하여 모델을 정제한 모델을 필요에 따라 다시 reasoning 모델로 발전시킨다.
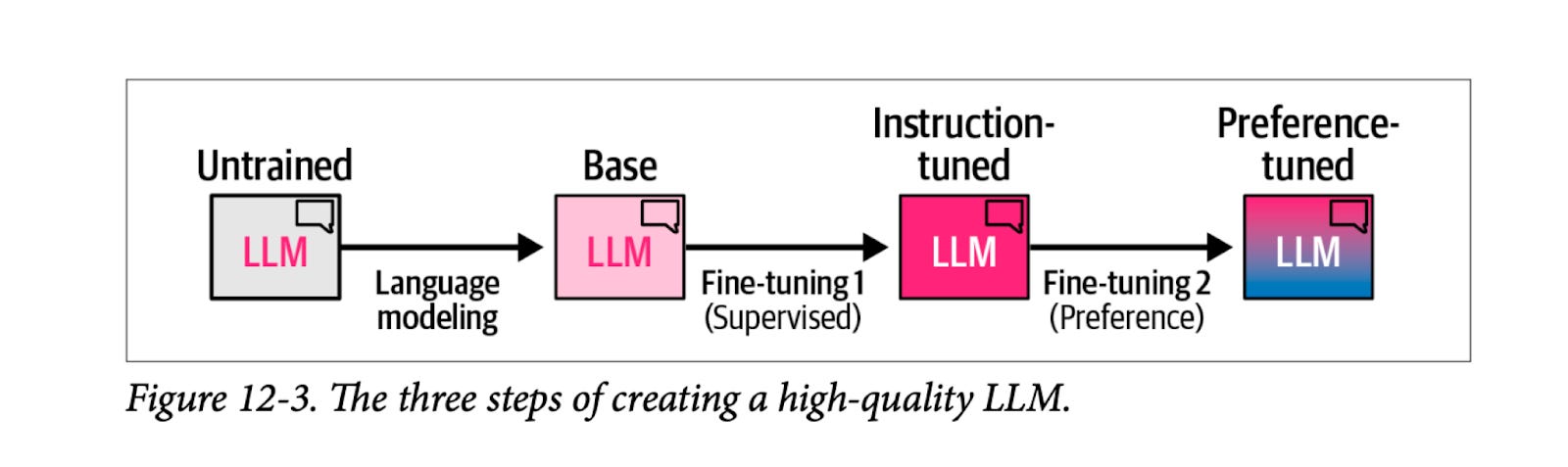
📌 Traditional Pipeline
- DeepSeek‑R1의 Train Pipeline
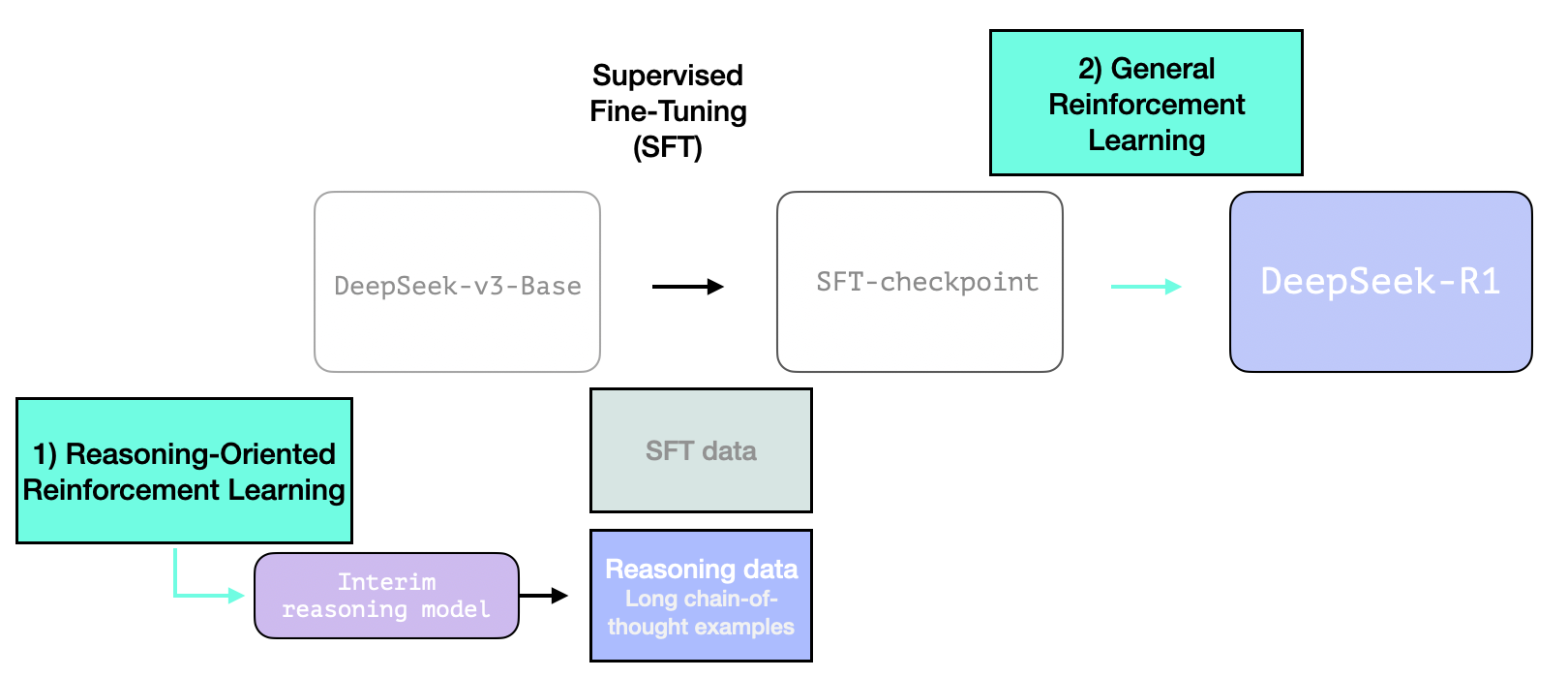
- DeepSeek‑R1은 Pre‑training 단계 후, Base 모델을 기준으로 R1-Zero를 이용해 생성한 Cold Start Data로 Interim Reasoning Model을 먼저 구축한다.
- 이후, 대규모 reasoning RL을 적용하여 RL checkpoint를 만든다.
- RL checkpoint를 기반으로 거대한 Reasoning SFT 데이터를 생성하고, SFT를 적용한다.
- SFT checkpoint로부터 다시 일반 RL을 진행하여 최종 R1 모델을 구축한다.
📌 R1 Pipeline
Traditional Pipeline
전통적인 학습 파이프라인은 방대한 Pre‑training을 통해 기본 언어모델을 구축한 후, SFT를 통해 instruction 및 일반 태스크에 특화된 학습을 진행하며, 이후 Preference Tuning(RL)을 거쳐 모델이 사용자의 선호도에 맞게 정렬되도록 한다.
SFT(Supervised Fine-Tuning)
- 소개:
- SFT는 prompt와 정답(completion) 쌍을 모델에 학습시켜, 모델이 주어진 instruction을 정확히 따르고 질문에 적절히 응답하도록 만드는 단계이다.
- 정의:
- 일반적인 SFT에서는 수십만~수백만 건의 레이블 데이터를 활용하여, 모델이 다양한 태스크에 대해 빠르게 적응할 수 있도록 한다.
RL(Reinforcement Learning)
- 하는 이유:
- 단순 SFT만으로는 모델이 추론 과정에서 인간 선호도 등을 반영한 친화적인 답변을 내놓기는 힘들다.
- Methods:
- RL의 methods로는 RLHF, DPO, GRPO 등 그 방법과 장단점이 다양하나, 이번에 자세히 다루지는 않는다.
CoT(Chain of Thought)
- 소개:
- SFT, RL 2가지 방법으로 모두 가능하며, Reasoning model은 답변 과정에서 추론 단계 토큰을 생성, 스스로 생각하는 과정을 거친후 최종 답변을 한다.
- 하는 이유:
- 수학, 코딩, 논리 문제 등 복잡한 태스크에서 단순 정답 외에도 문제를 푸는 과정을 설명함으로써, 모델이 명확한 인과관계를 통해 답하도록 한다.
- 형식:
- 특정 태그들을 이용하여 중간 추론 단계를 만든 후 해당 단계의 생성 토큰들을 다시 참고하여 답변한다.
R1 Pipeline
-
DeepSeek‑R1의 파이프라인은 기존의 전통적인 방식과 달리, Base 모델에서 시작하여 바로 순수 강화학습(RL) 기반의 R1-Zero를 구축한다.
-
이를 활용해 고품질 Reasoning 데이터(Cold Start Data)를 생성, 해당 데이터를 기반으로 RL을 진행하여 RL 초기의 cold start 단계에서 불안정성을 완화한 Interim Reasoning Model을 구축한다.
- 이후, Interim Reasoning Model을 R1-Zero처럼 대량의 reasoning data로 RL을 진행하며, 이 단계에서는 cold-start 때에는 없었던 language consistency reward를 추가하여, 보다 읽기 좋고 일관된 CoT를 생성하도록 유도한다.
- RL 학습이 수렴한 후, checkpoint로부터 rejection sampling을 통해 reasoning 뿐만 아니라 아니라 writing, factual QA 등 일반 영역의 데이터도 포함된 약 80만개의 SFT 데이터를 수집한다.
- 수집된 데이터로 SFT를 진행한 후, general RL을 거쳐서 최종 R1 모델을 완성하는 방식이다.
R1-Zero
- 소개:
- R1-Zero는 R1 pipeline 이전의 실험적 모델로, SFT 없이 Base 모델에서 직접 RL을 적용해 Reasoning 능력을 극대화한 모델이다.
-
만든 이유:
- Base 모델 이후 대량의 SFT 데이터 없이 reasoning 능력을 끌어올릴 수 있는 지 실험하려고.
-
활용:
-
RL 초기의 불안정한 cold start 단계를 피하기 위해, R1-Zero로 부터 few shot prompting으로 생성한 긴 CoT 예시가 담긴 소량(수천 개)의 데이터로 GRPO를 적용한 Base model을 RL actor로 활용하기 위함이다.
-
다양한 평가 기준(예: 정답의 형식, 규칙 기반 검증을 통한 정확도 평가 등)을 통해 모델이 자체적으로 보상 신호를 얻으며 학습할 수 있기 때문에, 해당 기준에 부합하는 cold start data를 생성하여 대규모 RL 전에 미리 학습해둔다면, 이후 다른 reward들을 포함한 대규모 RL에서 cold start의 불안정함을 완화할 수 있다.
-
-
약점:
- Reasoning 태스크에서는 뛰어난 성능을 보이나, 출력 형식이 불안정(예: 가독성 저하, 언어 혼합 현상)하여 사용자 친화적이지 못한 문제가 있다.
- 강점:
- Base 모델에 소량의 고품질 Reasoning 데이터만 추가하더라도, 모델의 Reasoning 능력이 급격히 향상되는 잠재력을 보여준다.
📌 R1‑Zero

Cold Start Data
- 정의:
- Interim Reasoning Model을 만들기 위해, R1-Zero로 부터 few-shot prompting을 통해 수천 개 규모의 reasoning 문제 예시를 생성한다. 이를 cold start data라고 부른다.
📌 Cold Start Data

R1 Flow
- 학습 상세:
- SFT
- Reasoning(Long CoT) 데이터는 Interim Reasoning Model의 rejection sampling을 통해 약 60만 건으로 정제된다. SFT 데이터는 약 20만 건 정도로, 다양한 도메인(코딩, 수학, 일반 QA 등)에서 수집되며, DeepSeek‑V2.5 기반 생성 후 인력 검증을 거친다.
- 위 데이터를 기반으로, 수집된 Reasoning 및 Non‑Reasoning 데이터를 활용해 2 epochs 동안 fine-tune한다.
- RL
- PPO 및 GRPO 기법을 활용하여, 모델이 각 태스크(수학, 코딩, 논리 문제 등)에 대해 높은 정확도와 일관성을 갖도록 추가 RL을 진행한다.
- SFT
- R1 Pipeline:
- Pre-train(Empty model -> Base model)
- Cold Start Data 구축
- 안정적인 RL 시작을 위해, 읽기 쉽고 긴 CoT 형식의 high-quality 데이터를 수집
- R1-Zero의 few-shot prompting 출력 재가공, human annotator의 후처리를 통해 생성
- Cold start data RL(Base model -> Interim Reasoning Model)
- Language consistency 등의 reward들을 추가한 대규모 RL(Interim Reasoning Model -> Reasoning Checkpoint)
- SFT Data 구축
- 일반 instruction data 20만건
- Reasoning Checkpoint를 통해 rejection sampling한 long CoT data 60만건
- SFT(Reasoning Checkpoint -> SFT Checkpoint)
- General RL(SFT Checkpoint -> R1)
-
차별점:
-
Reinforcement Learning 기반 자율 학습:
- R1-Zero, R1에서는 초기 supervised fine-tuning 없이 base 모델에서 pure RL을 적용하여 모델이 스스로 reasoning 능력을 발전시키도록 하여, 모델이 스스로 문제 해결 전략을 찾고 aha moment와 같은 자발적 개선 단계를 가진다.
Cold Start Data를 통한 안정적 시작:
- R1은 RL 초기 단계에서의 불안정함을 방지하기 위해, 소량이며 고품질인 긴 CoT 데이터를 cold start data로 수집 및 활용한다. 이 데이터는 읽기 쉽고 일관된 reasoning 과정을 제공하여, 초기 모델을 안정화시키고 RL의 효율성을 높인다.
후속 SFT 및 데이터 혼합:
- RL이 어느 정도 수렴한 후, rejection sampling을 통해 추가 데이터를 수집하고, reasoning 외의 다양한 태스크(글쓰기, QA 등) 데이터와 혼합하여 supervised fine-tuning을 진행한다. 이를 통해 모델의 범용성과 출력의 가독성을 함께 개선한다.
-
-
장점:
- 자율적 발전 및 적응성:
- RL을 통해 모델이 스스로 reasoning 전략을 탐색하고 개선함으로써, 명시적으로 정해진 답안 패턴에 의존하지 않고 유연하게 문제에 대응할 수 있다.
- 향상된 출력 가독성:
- Cold start data를 활용해 읽기 좋고 일관된 CoT를 유도함으로써, 답안 뿐만 아니라 전체 reasoning 과정이 명확하게 표현된다.
- 성능 및 일반화 개선:
- 초기 pure RL과 후속 SFT 단계를 결합하여, 기존의 SFT-only 방식보다 빠르게 성능이 향상되고, 다양한 태스크에서 강력한 reasoning 능력을 보인다.
- 효율적 데이터 활용:
- 소량의 고품질 데이터를 기반으로 시작, 이후에 대규모 데이터를 추가하는 방식은 데이터 수집 비용과 시간을 절감하며, 모델의 성능 또한 극대화한다.
- 자율적 발전 및 적응성:
Distillation
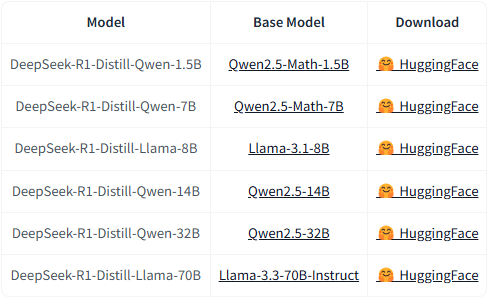
- Models:
- DeepSeek‑R1의 강력한 Reasoning 능력은 소형 모델에도 효과적으로 전이시킬 수 있다. 이를 위해 DeepSeek‑R1이 생성한 고품질 reasoning data를 활용하여, Qwen 및 Llama 기반의 소형 모델(1.5B, 7B, 8B, 14B, 32B, 70B)로 증류한다.
- Method:
- R1에서 생성한 고품질 Reasoning 데이터 샘플로 상대적 소형 dense model에 SFT한다. 이 방식은 추가 RL 단계 없이도, teacher 모델의 Reasoning 능력을 소형 모델에 효과적으로 내재화시킨다.
Method
DeepSeek‑R1을 사용하여 Reasoning 데이터셋을 생성하고, 이를 기반으로 소형 모델을 SFT한다.
📌 Distillated models
Performance
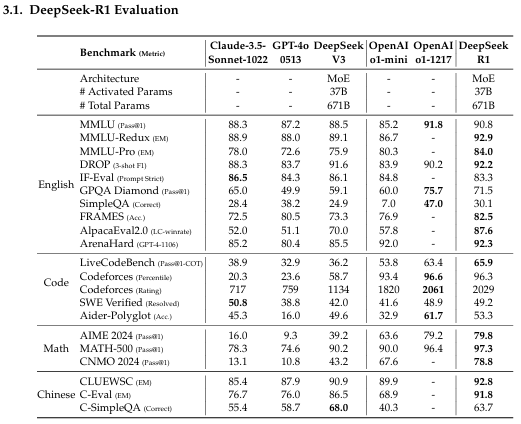
DeepSeek‑R1은 AIME 2024, MATH‑500, Codeforces, MMLU 등 다양한 Reasoning 벤치마크에서 OpenAI‑o1‑1217과 유사하거나 그 이상의 성능을 보여준다. 특히, 수학 및 코딩 태스크에서 뛰어난 능력을 확인할 수 있다.
📌 Performance
후기
DeepSeek‑R1은 Interim Reasoning Model을 활용해 효율적으로 reasoning 성능을 끌어올린 첫 케이스로, 다음과 같은 점에서 주목할 만하다.
- R1의 학습 방식의 장점:
- DeepSeek‑R1은 소량의 고품질 Cold Start Data와 순수 RL을 통해, 훨씬 적게 확보된 초기 데이터로도 강력한 Reasoning 능력을 확보했다.
- 효율성 증대를 위한 노력:
- R1 Pipeline은 Base model에서 바로 Interim Reasoning Model 구축 및 SFT 데이터를 효과적으로 생성하는 전략으로 Traditional Pipeline 대비 뛰어난 학습 효율을 낸다.
- 또한, Distillation을 통해 소형 Reasoning 모델로도 확장하여 실용성을 높였다.
댓글남기기