DeepSeek-V3 Review
DeepSeek-V3 Review
👉🏻논문 링크
DeepSeek-V3에 대한 리뷰는 이미 많이 나왔지만, 단순한 성능 비교나 벤치마크 결과를 나열하는 것을 넘어 최적의 성능을 끌어내는 트랜스포머 아키텍처 설계와 효율적인 학습을 위한 혼합 정밀도 활용에 집중하려 한다.
특히,
- 전통적인 디코더 기반 트랜스포머 모델에 다양한 기술을 적용해 지속적인 개선을 이루어 전반적인 효율 및 성능을 향상시킨 점
- Nvidia Hopper Architecture의 강점을 최대한 활용한 FP8 Mixed Precision 기법을 통해, 성능은 유지하면서도 자원 및 시간을 크게 절감한 점
- 학습 과정이 Pre-training, Post-training (SFT), Post-training (RL)으로 나뉘며, 각 단계별로 learning rate, 배치 사이즈, 데이터 출처 및 양 등이 체계적으로 조정된 점
이 세 가지 핵심 요소를 중심으로 DeepSeek-V3의 아키텍처와 학습 기법이 기존 모델과 어떤 차별점을 가지는지 살펴보자.
Architectures
DeepSeek-V3의 아키텍처는 기존의 전통적인 디코더 기반 트랜스포머 모델과 비교했을 때 세 가지 중요한 차이점을 가진다.
1. Multi-head Latent Attention (MLA)
기존 어텐션 메커니즘은 모델 크기가 커질수록 연산량과 메모리 사용량이 증가하는 문제가 있었다. DeepSeek-V3는 이를 해결하기 위해 MLA (Multi-head Latent Attention)라는 자체 어텐션 구조를 도입했다. MLA는 기존 Multi-Head Attention (MHA)와 달리 Q, K, V 행렬을 처음부터 LoRA (Low-Rank Adaptation) 방식으로 구성하고, K와 V를 하나의 projection에서 생성하여 파라미터 효율성을 극대화한다. 또한, MLA는 기존 RoPE (Rotary Position Embedding)와 함께 NoPE (No Position Embedding) 방식을 병행하여 다양한 위치 인코딩 전략을 적용하며, GQA (Grouped Query Attention) 및 MQA (Multi-query Attention) 방식을 혼합적으로 사용해 연산 효율과 성능을 동시에 확보한다.
2. Mixture of Experts (MoE)
MoE (Mixture of Experts)는 기존에도 널리 활용되던 기법이지만, DeepSeek-V3는 이를 한 단계 발전시켰다. 전통적인 MoE에서는 전문가 네트워크 간의 부하 불균형을 조절하기 위해 auxiliary loss를 추가로 사용했으나, DeepSeek-V3는 Auxiliary‑Loss Free Load Balancing을 도입해 별도의 손실 함수 없이도 전문가 간 부하가 자연스럽게 분산되도록 설계되었다. 또한, Bias‑Corrected Top‑k Gating Strategy 을 개발하여 특정 전문가가 과도하게 활성화되는 문제를 완화하고, 데이터 특성에 따라 동적으로 전문가를 할당할 수 있다.
3. Multi-Token Prediction (MTP)
DeepSeek-V3는 최근 트랜스포머 기반 모델들이 학습 단계에서 도입하는 Multi-Token Prediction (MTP) 기법을 채택하였다. 기존 MTP 방식은 Medusa와 같이 여러 개의 LM Head를 배치해 각 Head가 개별적으로 토큰을 예측하는 형태였으나, DeepSeek-V3는 LM Head를 공유하면서 Transformer 블록 내에서 재귀적으로 MTP를 적용하는 방식을 도입해 파라미터 수 증가 없이 한 번의 forward pass에서 여러 토큰을 예측할 수 있도록 설계되었다. 단, 현재 공개된 추론 코드에는 해당 MTP 기법이 포함되어 있지 않아, 학습 과정에서의 구체적 적용 방식은 추가 검증이 필요하다.
이처럼, MLA, MoE, MTP 세 가지 핵심 기법 덕분에 DeepSeek-V3는 동일한 파라미터 규모 내에서 더 나은 성능과 연산 효율을 달성할 수 있다. 다음으로는 각 아키텍처에 대해 더욱 상세히 분석해보자.
Multi-head Latent Attention(MLA)
DeepSeek-V3에서 가장 눈에 띄는 차별점 중 하나는 Multi-head Latent Attention(MLA)이다. 기존의 트랜스포머 모델에서 사용되는 Multi-Head Attention(MHA)는 각 헤드마다 독립적인 Key(K)와 Value(V)를 생성하는 방식이었지만, MLA는 이를 개선하여 연산량과 메모리 사용량을 줄이면서도 성능을 유지하는 방식을 도입했다.
1. MLA의 핵심 개념
일반적인 트랜스포머에서는 Q, K, V 행렬을 각 헤드마다 독립적으로 생성하지만, DeepSeek-V3의 MLA는 LoRA(Low-Rank Adaptation) 기법을 활용하여 Q, K, V를 처음부터 경량화된 형태로 생성한다. 특히, K와 V를 하나의 projection에서 생성하는 구조를 갖추고 있어, 파라미터 수를 줄이면서도 유사한 어텐션 성능을 유지할 수 있도록 설계되었다.
📌 논문에서 MLA figure
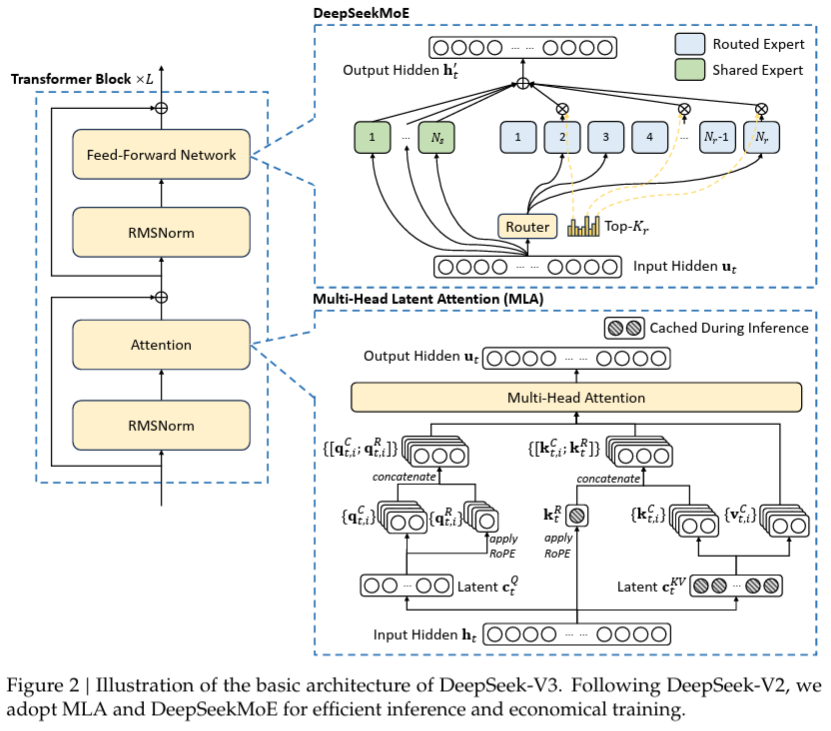
2. RoPE & NoPE: MLA에서의 위치 인코딩 방식
MLA는 RoPE(Rotary Position Embedding)와 NoPE(No Position Embedding)를 동시에 지원하는 구조를 갖추고 있다.
-
RoPE는 거의 대부분의 modern transformer structure에 사용된 방식으로, 상대적 위치 정보를 어텐션 메커니즘에 자연스럽게 주입할 수 있는 강점을 가진다.
- NoPE는 특정한 위치 인코딩을 사용하지 않고, MLA 자체의 학습 과정에서 자연스럽게 패턴을 익히도록 하는 방식이다.
- MLA에서는 GQA(Grouped Query Attention) 및 MQA(Multi-Query Attention)를 동시에 활용할 수 있도록 설계되었다.
3. MLA와 General MHA의 차이점
기존의 Llama 등의 모델에서도 어텐션 최적화를 위한 여러 기법이 적용되었지만, MLA는 다음과 같은 추가적인 개선점을 포함하고 있다.
- LoRA 기반의 경량 Q, K, V 생성
- K, V를 하나의 projection에서 추출하여 메모리 효율성 증가
- RoPE 및 NoPE 선택 가능 (GQA, MQA 동시 활용)
📌 MLA 도식화
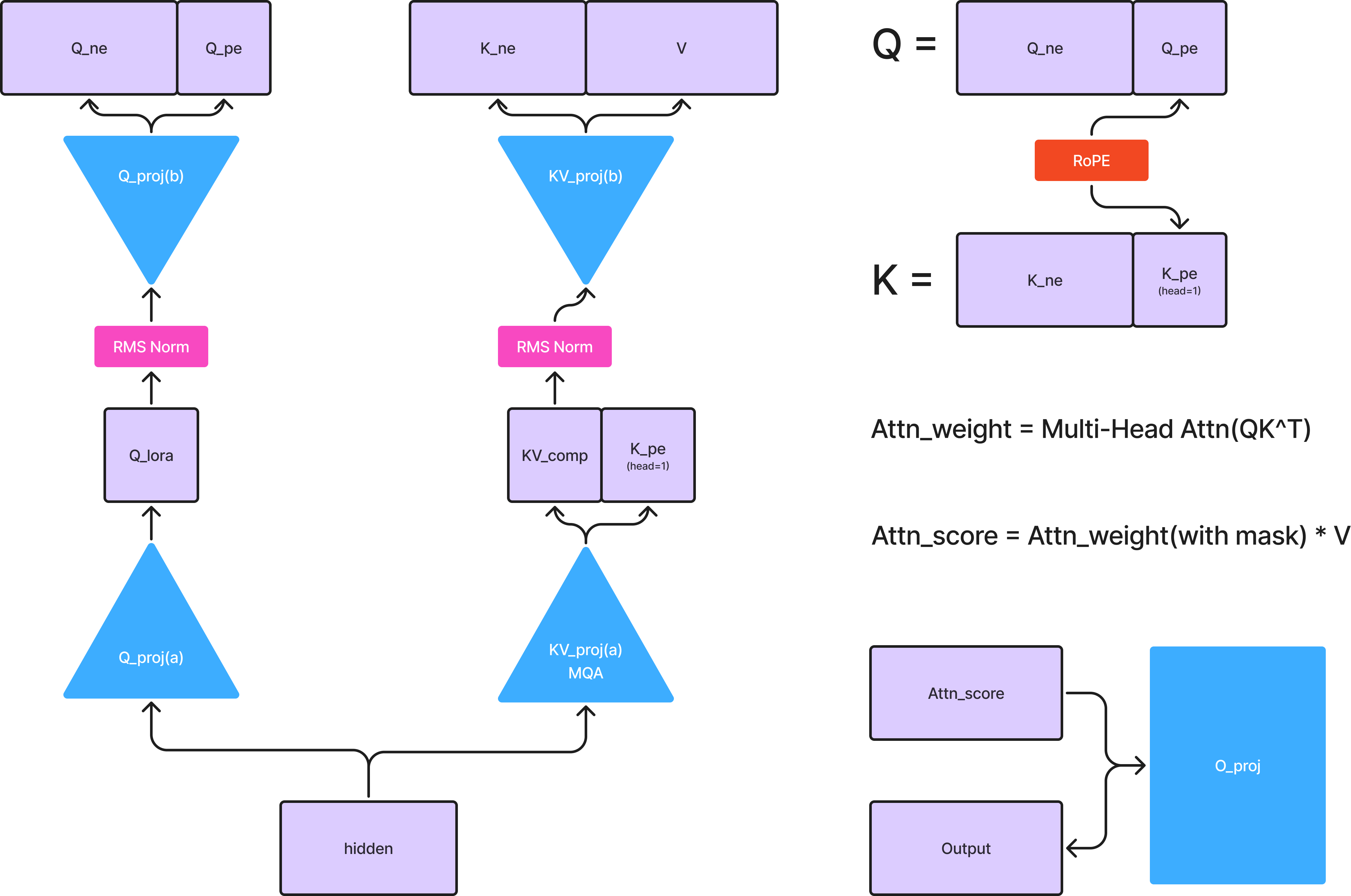
📌 General MHA(like Llama) 도식화
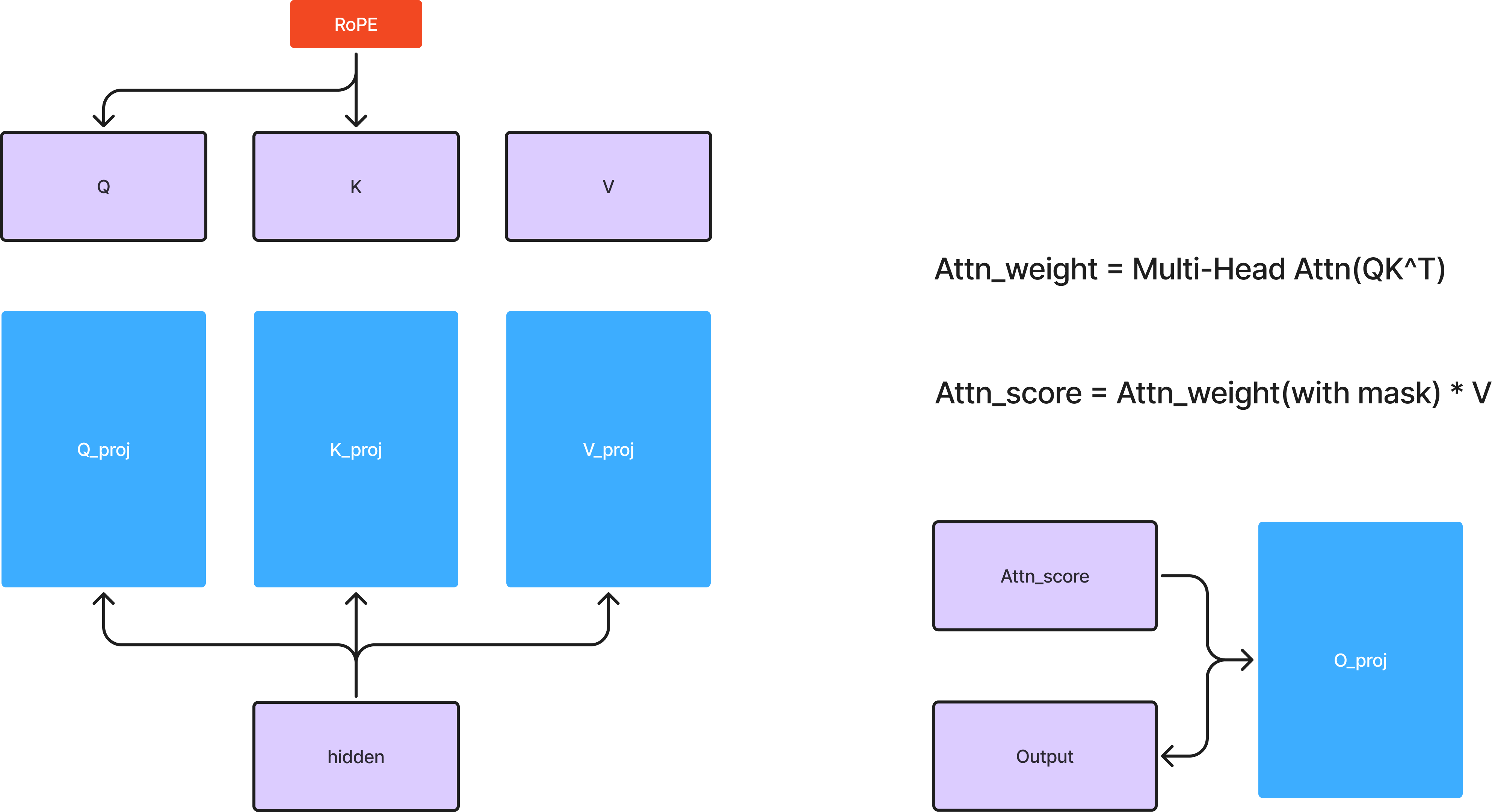
4. MLA의 성능 및 기대 효과
이러한 설계를 통해 MLA는 기존 MHA 대비 메모리 사용량을 줄이면서도 동일한 수준의 성능을 유지하는 데 초점을 맞췄다. 특히, LoRA를 활용한 Q, K, V 생성과 K, V의 단일 projection 사용으로 인해 연산량을 절감할 수 있다는 점이 큰 장점이다.
📌 MLA 공식 구현 코드(init)

📌 MLA 공식 구현 코드(forward)
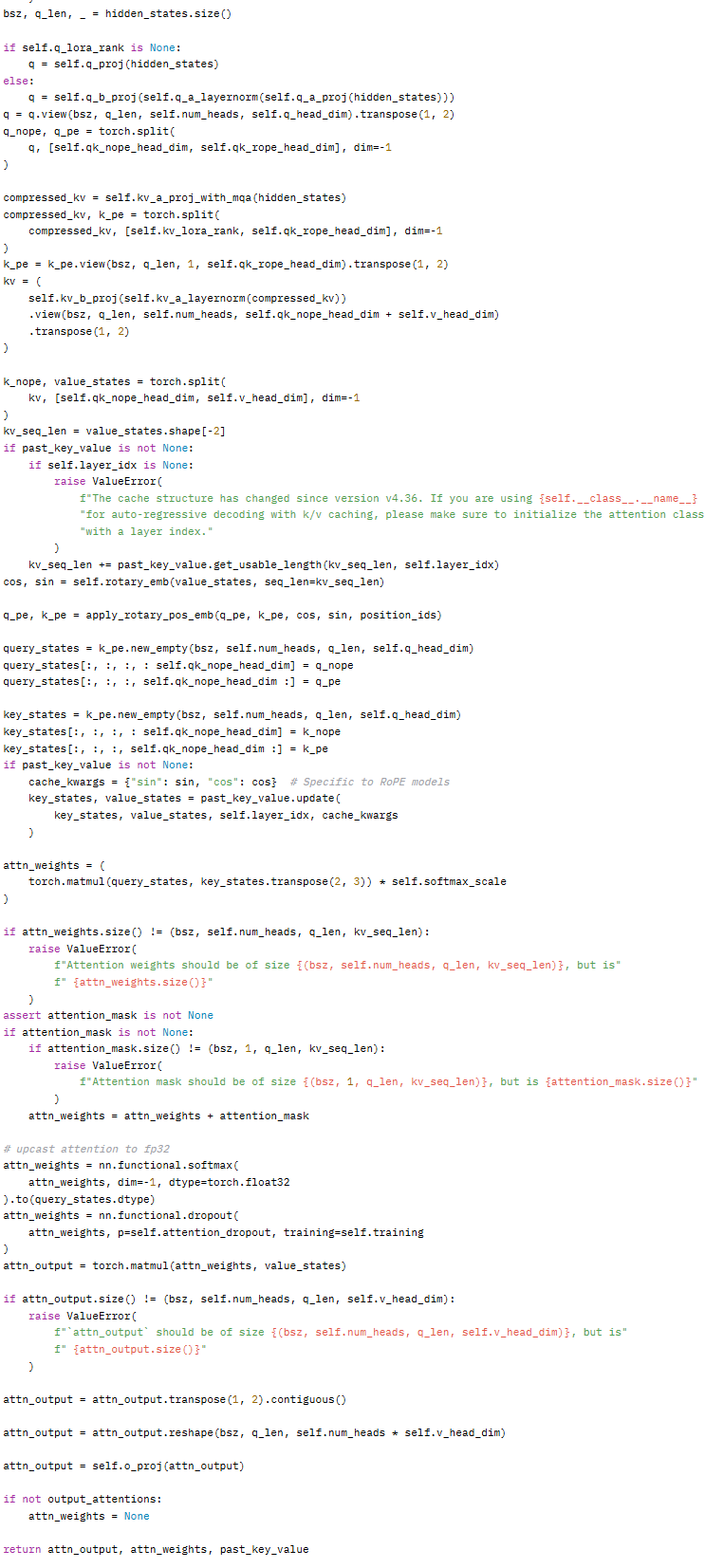
결론적으로, MLA는 기존 어텐션 구조에서 발생하는 메모리 및 연산량 문제를 효과적으로 개선하면서도 성능을 유지하는 독자적인 DeepSeek-V3의 핵심 아키텍처라 할 수 있다.
Mixture of Experts(MoE)
DeepSeek-V3는 기존에도 널리 사용되던 Mixture of Experts (MoE) 구조를 채택했지만, 단순한 MoE 모델이 아니라 효율성과 균형을 최적화한 새로운 전략을 도입했다. 일반적으로 MoE는 거대한 모델에서 연산량을 줄이면서도 성능을 유지할 수 있도록 하는 강력한 기법이지만, 전문가 네트워크 간의 부하 불균형(Load Imbalance) 문제와 추가적인 auxiliary loss 필요성이 단점으로 지적되어 왔다. DeepSeek-V3는 이러한 한계를 해결하기 위해 Auxiliary‑Loss Free Load Balancing과 Bias‑Corrected Top‑k Gating Strategy 기법을 도입했다.
1. MoE의 기본 개념
MoE는 여러 개의 전문가(Expert) 네트워크 중 일부만 활성화하여 모델의 연산 효율성을 극대화하는 방식이다. 일반적으로는 Gating Network가 입력을 받아 전문가를 선택하며, 선택된 전문가만 활성화된다. 이를 통해 거대한 모델도 일부 파라미터만을 사용하여 연산을 수행할 수 있으므로 추론 속도가 빨라지고 메모리 사용량이 감소하는 효과를 얻을 수 있다.
📌 논문에서 MoE figure
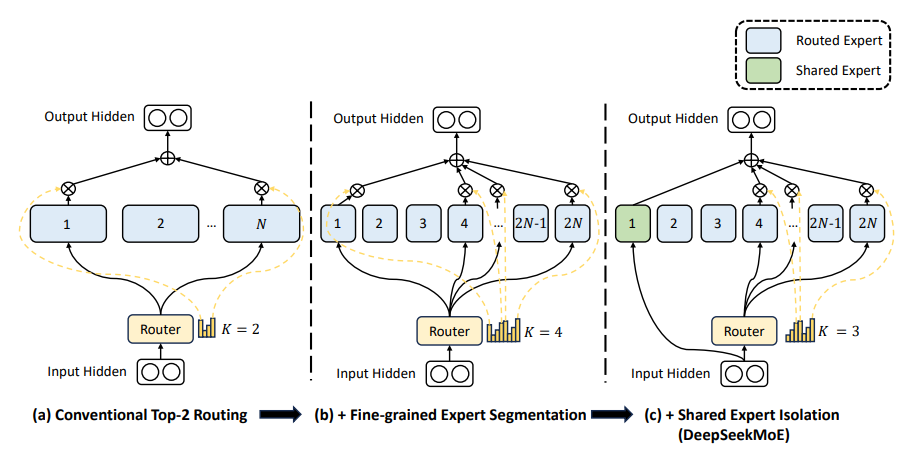
2. DeepSeek-V3의 MoE 개선점
DeepSeek‑V3의 MoE는 기존 MoE 모델이 가진 한계를 극복하기 위해 두 가지 핵심 전략을 도입했다.
(1) Auxiliary‑Loss Free Load Balancing
기존 MoE 모델은 일부 전문가(Expert)만 지나치게 활성화되는 routing collapse 문제를 해결하기 위해 보통 auxiliary loss를 추가하여 전문가 부하(load)를 균형 있게 분배한다. 그러나 auxiliary loss는 다음과 같은 대표적인 2가지 단점이 있다.
- 추가적인 계산 비용을 발생시킨다.
- 최적의 loss balancing을 위한 hyperparameter 튜닝이 까다롭다.
DeepSeek‑V3는 bias term을 각 전문가에 도입하여, routing 단계에서 각 전문가의 affinity score에 보정값을 더해 top‑k 선택을 수행한다.
- Affinity Score 계산: 입력 토큰과 전문가의 centroid 간 내적과 sigmoid 함수를 이용하여 affinity score를 계산한다.
- Bias 적용 및 동적 조정: 각 전문가별 bias를 score에 더해, 과도하게 선택되는 전문가는 bias를 낮추고, 덜 선택되는 전문가는 bias를 높여 동적으로 전문가 부하를 조절한다.
이로써 추가적인 auxiliary loss 없이도 전문가들이 균형있게 활용될 수 있다.
- 모델 학습이 단순해지고 최적화가 용이해진다.
- 별도의 hyper-parameter 튜닝 부담 없이 안정적인 학습이 가능해진다.
📌 논문에서 Auxiliary‑Loss Free Load Balancing 설명

(2) Bias‑Corrected Top‑k Gating Strategy
일반적인 MoE에서는 고정된 Top‑k 방식으로 전문가를 선택하는 경우가 많아, 일부 전문가가 지나치게 자주 호출되는 문제가 발생한다. DeepSeek‑V3에서는 다음과 같은 방법으로 이를 개선했다.
- Sigmoid 기반 Affinity Score: 입력 토큰과 전문가 centroid 간 내적으로 계산한 affinity score를 사용하여 전문가 간 유사도를 정량화한다.
- Top‑k 선택 및 그룹화: 계산된 score에 bias term을 더한 후, 그룹 단위로 top‑k 전문가를 선택, 각 토큰에 대해 가장 적합한 전문가들을 동적으로 할당한다.
- 정규화: 선택된 전문가들의 score는 정규화되어, 각 전문가의 FFN 결과에 곱해짐으로써 최종 출력에 반영된다.
이 방법은 다음과 같은 장점을 가진다.
- 데이터 특성에 맞게 유동적으로 전문가가 선택될 수 있다.
- 특정 전문가가 독점적으로 활성화되는 문제를 효과적으로 방지할 수 있다.
- 추가적인 auxiliary loss 없이도 load imbalance 문제를 해결한다.
📌 DeepSeek V3 공식 구현 코드의 MoE forward 부분

3. DeepSeek-V3 MoE의 장점
DeepSeek‑V3는 위의 두 전략을 통해 기존 MoE 모델 대비 다음과 같은 장점을 가진다.
✅ 불균형 문제 해결 → Bias term을 활용한 동적 부하 조절로 특정 전문가의 과도한 활성화를 방지
✅ 추가적인 Loss 없이 안정적 학습 → auxiliary loss를 사용하지 않아 학습 구조가 단순하며, 튜닝 부담이 줄어듦
✅ 연산 비용 절감 → 효율적인 gating 전략으로 불필요한 전문가 호출을 최소화
✅ 추론 속도 향상 → 동적이고 정규화된 전문가 선택을 통해 최적의 계산 경로를 확보
결과적으로, DeepSeek‑V3의 MoE는 기존 MoE 모델의 한계를 극복하면서도 효율적이고 안정적인 전문가 선택 구조를 갖추고 있다고 할 수 있다.
Multi-Token Prediction(MTP)
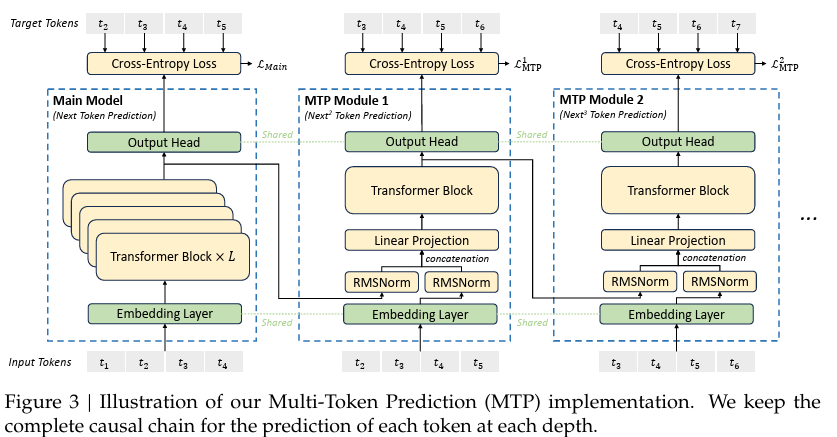
DeepSeek-V3는 최근 많은 트랜스포머 기반 모델이 학습 단계에서 적용하는 방법인 Multi-Token Prediction(MTP) 기법을 마찬가지로 학습 때 적용하여 성능을 극대화했다. 일반적으로 트랜스포머 기반 언어 모델은 한 번에 한개의 토큰을 생성하지만, MTP를 적용하면 한 번의 Forward Pass에서 여러 개의 토큰을 동시에 예측 및 비교하여 Loss Backward 하므로 성능을 개선할 수 있다.
DeepSeek-V3의 technical report에서는 figure를 통해 개선된 MTP 기법을 소개하였으나, 공개된 모델링 코드는 추론을 위한 구성만 포함하고 있으며, 실제 학습에서 DeepSeek MTP의 구체적인 hyper-parameters는 자세히 알 수 없다. 따라서 이번 리뷰에서는 구체적인 코드나 적용을 제외하되, 기존 MTP 기법을 소개하고, DeepSeek-V3의 MTP 방식이 어떤 차별점을 가지는지 살펴보려 한다.
1. 기존 MTP 방법론
기존의 MTP 방식은 주로 Parallel Decoding 기법을 활용하여 학습 능력을 높이는 데 집중해왔다. 대표적인 접근 방식은 다음과 같다.
(1) Standard MTP (기본 MTP)
기본적인 MTP 방식은 각 Step에서 다음 k개의 토큰을 예측하는 구조를 가진다. 즉, 모델이 단일 토큰을 생성하는 것이 아니라, 한 번의 연산으로 k개의 토큰을 예측할 수 있도록 구성된다.
✅ 장점: 학습 능력 향상, 병렬 연산 가능
❌ 단점: 초기 예측이 잘못되면 이후 예측도 오류가 누적됨
📌 Standard MTP figure
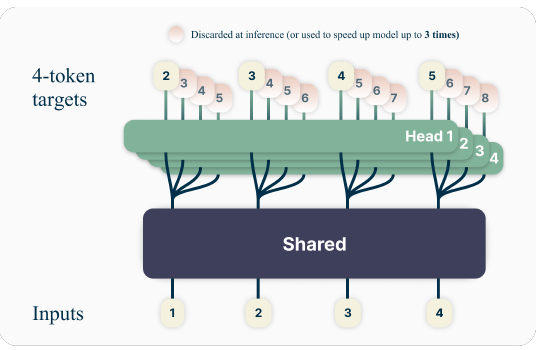
(2) Medusa MTP
Medusa MTP는 기존 MTP 방식과 달리 LM Head를 여러 개 배치하여 각 Head가 개별적으로 토큰을 예측하는 방식이다.
- Medusa에서는 각 LM Head가 서로 다른 위치의 토큰을 예측하며, 특정 패턴을 학습하도록 설계된다.
- 다만, Head를 여러 개 배치하면 모델의 크기가 증가하고 연산량이 많아진다는 단점이 있다.
📌 Medusa MTP figure
2. DeepSeek-V3의 MTP 차별점
DeepSeek-V3는 MTP를 적용하는 방식에서 기존 방식들과 큰 차이점을 가진다.
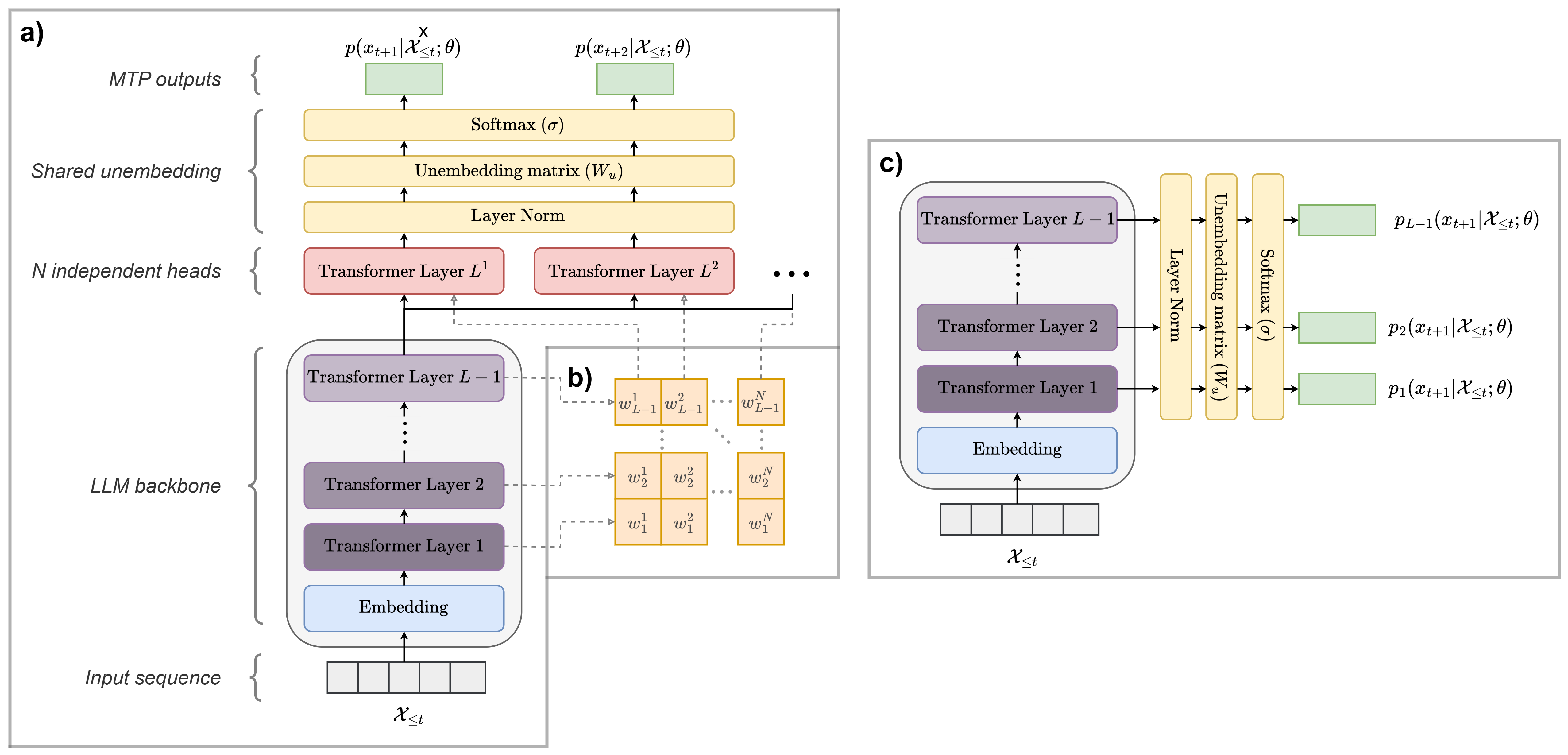
✅ LM Head를 여러 개 배치하는 것이 아니라 공유하는 방식을 사용한다.
✅ Transformer 블록에서 재귀적으로 MTP를 적용하는 형태로 설계되었다.
✅ 이러한 구조는 모델 크기를 증가시키지 않으면서도 MTP를 활용할 수 있도록 한다.
📌 DeepSeek MTP figure
3. DeepSeek-V3의 MTP 방식이 주는 장점
DeepSeek-V3의 MTP 방식은 기존 방식 대비 다음과 같은 장점을 가진다.
✅ 모델 크기 증가 없이 MTP 활용 가능 → 기존 방식들은 LM Head를 여러 개 배치해야 했으나, DeepSeek-V3는 공유된 LM Head를 활용하여 MTP를 구현했다.
✅ 일반적인 MTP보다 안정적 → 기존 방식들은 초기 토큰 예측이 틀리면 이후 예측에도 영향이 컸지만, DeepSeek-V3는 Transformer 블록 자체에서 재귀적으로 MTP를 적용하여 이를 보완했다.
4. 미공개된 학습 과정
DeepSeek-V3의 공개된 코드는 추론 모델을 위한 코드이며, 실제 학습 과정에서 MTP가 어떤 방식으로 적용되었는지는 확인할 수 없다.
- 학습 시 MTP 적용 방식이 다를 가능성이 있으며, Transformer 블록에서의 재귀적 적용이 학습 시 어떻게 사용되는지는 불분명하다.
- 특히, MTP 적용 시 Beam Search나 Sampling 기법과 어떻게 조합되었는지에 대한 정보가 제공되지 않아 구체적인 학습 메커니즘을 확인할 수 없다.
결론적으로, DeepSeek-V3의 MTP는 기존 Medusa 방식과 달리 LM Head를 공유하면서 Transformer 블록 내에서 MTP를 활용하는 독자적인 방식을 적용했다. 다만, 학습 과정에서의 세부 구현이 공개되지 않았기 때문에 실제 성능 차이를 정확하게 평가하기는 어렵다.
Mixed Precision
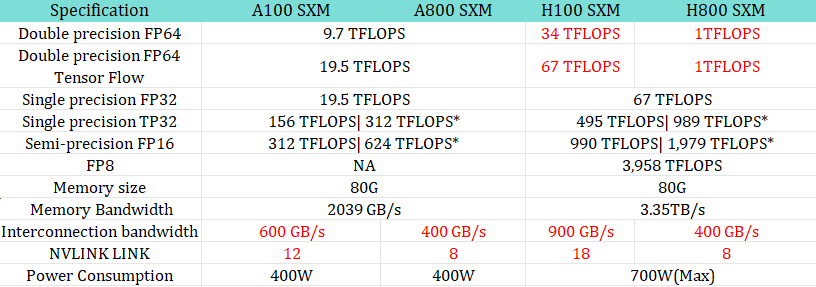
DeepSeek-V3는 Nvidia Hopper 아키텍처의 특징을 극대화하기 위해 FP8, BF16, FP32를 적절히 혼용하는 혼합 정밀도 전략을 채택하였다. 특히, 대중국 GPU 규제로 인해 H100 대신 H800를 사용하지만, H800도 Hopper 아키텍처 기반이므로 최신 FP8 연산 최적화 기능을 지원한다.
📌 H100 vs H800
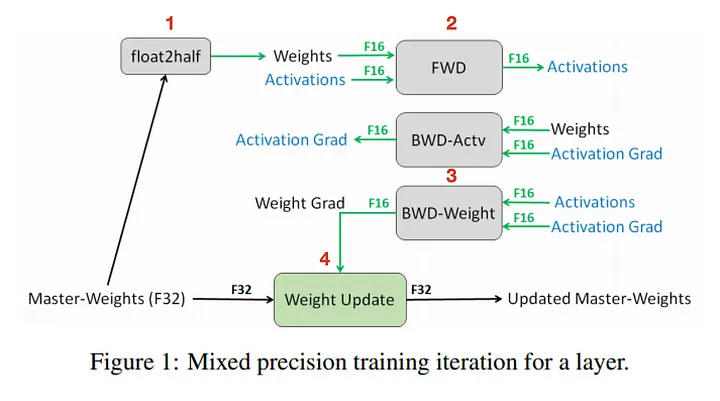
General Mixed Precision
과거 Ampere 아키텍처에서는 BF16 혼합 정밀도가 주류를 이루며,
- wgrad (Weight Gradient) 및 dgrad (Data Gradient) 연산이 최적화되어 FP32 대비 최대 3~4배 빠른 연산 성능을 보였다.
- Tensor Core의 최적화 덕분에 기존 FP32 대비 에너지 효율과 메모리 사용량 측면에서도 큰 이점을 제공하였다.
📌General Mixed Precision Figure
📌이해를 돕기 위한 wgrad, dgrad의 forward & backward calculation 예시








Mixed Precision Training의 장점:
- 연산 가속: Tensor Core 및 최적화된 mixed precision 연산 덕분에 학습 속도가 크게 향상됨
- 메모리 절감: 낮은 정밀도 사용으로 메모리 소비를 줄임
- 에너지 효율: 연산 정밀도 하락에 따른 전력 소모 감소
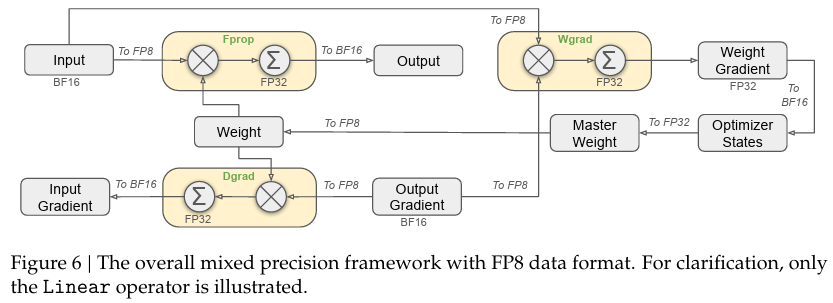
FP8 Mixed Precision
Hopper 아키텍처는 FP8 연산 지원을 통해 BF16/FP32 대비 최대 1.2~1.5배 빠른 연산 성능을 제공한다. 다만, FP8는 정밀도가 약 8비트로 낮아 계산 시 표현력에서 손실이 발생할 수 있다. DeepSeek‑V3는 이를 극복하기 위해 다음과 같이 정밀도를 혼용한다.
- FP8:
- 주로 어텐션 연산과 대규모 행렬 곱셈과 같이 연산량이 방대하지만, 정밀도 손실이 보완 가능한 부분에서 사용한다.
- 스케일 팩터 (Loss Scaling): 동적 스케일링을 통해 FP8 연산의 underflow/overflow 문제를 완화하며, 연산 결과를 BF16나 FP32로 누적한다.
- BF16:
- 활성화 계산 및 중간 결과 처리에 사용되어 FP8보다 높은 정밀도를 보장하면서도, FP32보다 연산 속도와 메모리 효율이 좋다.
- FP32:
- 가중치 업데이트와 같이 누적 오차가 모델 성능에 큰 영향을 주는 단계에서 사용된다.
이러한 하이브리드 전략 덕분에 DeepSeek‑V3는 FP8의 빠른 연산 속도와 BF16/FP32의 안정성을 동시에 확보할 수 있다.
GPU Hours 비교:
- LLaMA: H100 16,384개 GPU 클러스터를 사용, 3.1 405B의 경우 → 30,840,000 H100 GPU hours
- DeepSeek‑V3: H800 2,048개 GPU를 사용, 기술 리포트에 따르면 Pre-training 단계에서 약 12시간 동안 학습 → 2,048 × 12 = 24,576 H800 GPU hours
이처럼 DeepSeek‑V3는 상대적으로 적은 수의 GPU(규제 상 H800)를 사용하면서도, FP8 혼합 정밀도 및 효율적인 자원 활용 덕분에 안정적인 학습을 수행하였다.
📌 DeepSeek FP8 Mixed Precision
Hyper-Parameters
DeepSeek‑V3의 학습 과정은 Pre-training, Post-training (SFT), Post-training (RL)의 세 단계로 구분되며, 각 단계별로 데이터의 종류와 양, 학습 하이퍼파라미터(learning rate, optimizer 세부 설정, scheduler, 배치 사이즈 등)가 체계적으로 조정되었다. 아래는 DeepSeek‑V3 기술 리포트와 관련 문서를 토대로 작성한 구체적인 수치 및 설정 내용이다.
Pre-training
1. Data Construction
-
데이터 규모 및 특성:
-
토큰 수: 14.8T 고품질 토큰
-
데이터 최적화: 수학 및 프로그래밍 샘플 비율을 강화하고, 영어·중국어를 넘어 21개 이상의 언어를 포함
-
데이터 처리: 중복 제거와 다양성 유지를 위해 문서 패킹(document packing) 기법 적용
-
Fill‑in‑Middle (FIM) 전략:
-
구조: Prefix‑Suffix‑Middle (PSM) 프레임워크
-
포맷:
Copy <|fim_begin|> f_pre <|fim_hole|> f_suf <|fim_end|> f_middle <|eos_token|> -
적용 비율: 10% (0.1)
-
-
-
Tokenizer:
- Byte‑level BPE 방식
- 확장된 어휘 크기: 128K 토큰
- 다국어 압축 효율 최적화를 위한 pre‑tokenizer 개선 (구두점 및 개행 결합 토큰 처리, 학습 시 일부 분할 적용)
2. Model Hyper‑Parameters
- 모델 구성:
- Transformer Layers: 61
- Hidden Dimension: 7168
- 초기화 표준편차: 0.006
- Multi‑head Latent Attention (MLA):
- Attention Heads (nₕ): 128
- Per‑head Dimension (dₕ): 128
- KV Compression Dimension (d_c): 512
- Query Compression Dimension (d′_c): 1536
- Decoupled Query/Key per‑head dimension (dₕᴿ): 64
- MoE (Mixture of Experts) 설정:
- FFN: 첫 3개 레이어를 제외한 모든 FFN을 MoE 레이어로 대체
- 각 MoE 레이어:
- 1 shared expert + 256 routed experts
- 각 expert의 중간 hidden dimension: 2048
- 각 토큰 당 활성화되는 routed experts: 8개
- 각 토큰은 최대 4개 노드로 분산 (노드 제한 M = 4)
- Multi‑Token Prediction (MTP):
- 예측 깊이 (D): 1 (정확한 다음 토큰 외에 추가로 1개 예측)
- 전체 파라미터:
- 총 파라미터: 671B
- 토큰 당 활성화 파라미터: 37B
3. Training Hyper‑Parameters
-
Optimizer:
- AdamW (β₁ = 0.9, β₂ = 0.95, weight_decay = 0.1)
-
Sequence Length & 토큰:
- 최대 시퀀스 길이: 4K
- 전체 학습 데이터: 14.8T 토큰
-
Learning Rate 스케줄링:
-
초기 Warmup:
- 0 → 2.2×10⁻⁴, 첫 2K steps 동안 선형 증가
-
Constant Phase:
- 2.2×10⁻⁴ 유지 (모델이 10T 토큰 소비 시까지)
-
Cosine Decay:
- 10T ~ 14.3T 토큰 소비 구간에서 2.2×10⁻⁴에서 2.2×10⁻⁵로 점진적 감소 (약 4.3T 토큰 구간)
-
최종 Phase:
-
마지막
500B 토큰
동안:
- 첫 333B 토큰: lr = 2.2×10⁻⁵
- 남은 167B 토큰: lr = 7.3×10⁻⁶
-
-
-
Gradient Clipping:
- Norm 값: 1.0
-
Batch Size 스케줄링:
- 초기: 3072
- 첫 469B 토큰 소비 구간에서 점진적으로 15360까지 증가
- 이후 고정: 15360
-
병렬 처리:
- Pipeline parallelism 활용
- 각 레이어의 routed experts는 8 노드 내 64 GPU에 균등 배포
-
추가: Auxiliary‑loss‑free load balancing:
- Bias update speed (γ):
- 처음 14.3T 토큰: 0.001
- 마지막 500B 토큰: 0.0
- Balance loss (α): 0.0001
- MTP Loss Weight (λ):
- 처음 10T 토큰: 0.3
- 이후 4.8T 토큰: 0.1
- Bias update speed (γ):
4. Long Context Extension
-
방법: DeepSeek‑V2와 유사하게 YaRN 기법 적용
-
추가 훈련 단계:
두 단계 (각각 1000 steps)
- Phase 1:
- 시퀀스 길이: 32K
- Batch Size: 1920
- Learning Rate: 7.3×10⁻⁶
- Phase 2:
- 시퀀스 길이: 128K
- Batch Size: 480
- Learning Rate: 7.3×10⁻⁶
- Phase 1:
📌 DeepSeek pre-training Hyper-Parameters


Post-training(SFT)
1. Data Construction
- 인스트럭션 튜닝 데이터: 1.5M 인스턴스(다양한 도메인 포함)
- Reasoning Data:
- 내부 DeepSeek‑R1 모델을 활용해 생성
- <문제, 원본 응답> 및 <시스템 프롬프트, 문제, R1 응답> 두 가지 형식으로 구성
- Non‑Reasoning Data:
- 창의적 글쓰기, 역할극, 간단한 질의응답 등
- DeepSeek‑V2.5 기반 생성 후 인력 검증
2. Training Hyper‑Parameters
- 모델: DeepSeek‑V3‑Base
- Epoch 수: 2 epochs
- Learning Rate 스케줄링:
- 초기 lr: 5×10⁻⁶ (Cosine decay 방식으로 점진적으로 1×10⁻⁶까지 감소)
- 샘플 패킹 및 masking 전략 적용하여 개별 예제 간 상호 간섭 최소화
📌 DeepSeek post-training(SFT) Hyper-Parameters

Post-training(RL)
1. Reward Model Construction
- Rule‑Based RM:
- 특정 규칙으로 검증 가능한 문제(예: 수학 문제, LeetCode 문제)에 대해 규칙 기반 피드백 적용
- Model‑Based RM:
- 자유 형식 정답의 경우, SFT 체크포인트에서 훈련된 reward model을 활용하여 답변의 품질 평가
- 선호도 데이터에는 chain‑of‑thought도 포함해 reward hacking 방지
2. Group Relative Policy Optimization (GRPO)
- 기존 DeepSeek‑V2 방식과 유사하게, critic 모델 없이 그룹 내 출력의 baseline을 활용
- 목표 함수:
- 각 질문 q에 대해, 이전 정책(πθ_old)에서 그룹 {o₁, …, o_G}를 샘플링하고,
-
비율(πθ(oᵢ q) / πθ_old(oᵢ q))에 기반한 advantage Aᵢ (Aᵢ = rᵢ − mean({r₁, …, r_G})/std({r₁, …, r_G}))를 최대화
- 하이퍼파라미터: ε, β (정확한 값은 내부 실험을 통해 조정)
3. Data Construction
- 도메인: 코딩, 수학, 글쓰기, 역할극, 질의응답 등 다양한 영역
- SFT 데이터와 결합하여, 고온 샘플링을 통한 응답 생성 후 rejection sampling 적용
후기
DeepSeek‑V3를 리뷰하며, 제한된 자원 내에서도 최적의 효율과 성능을 달성하려는 연구진의 의지와 혁신적 기술에 감탄하게 되었다.
- 단순히 여러 기술들을 조합하는 것을 넘어서, MLA, MoE, MTP 등 각 구성 요소를 혁신적으로 개선하여 성능과 연산 효율성을 동시에 달성했다.
- Nvidia Hopper 아키텍처의 FP8 Mixed Precision 최적화는 FP32, BF16과의 하이브리드 운영을 통해 정밀도 손실을 최소화하면서도 빠른 연산을 가능하게 함
- FP8는 연산 집약적인 어텐션 및 피드포워드 네트워크에 적용되고, BF16는 활성화 및 중간 계산, FP32는 누적 및 가중치 업데이트에 사용된다.
- 동적 스케일링(스케일 팩터 적용)을 통해 FP8 연산의 정밀도 손실을 보완한다.
- Pre-training 단계에서는 점진적으로 learning rate와 batch size, 그리고 긴 문맥(long-context) 학습을 위한 별도 단계를 도입하여, 약 15T tokens 이상의 데이터를 효과적으로 학습했다.
- LLaMA의 경우 H100 16,384개 GPU 클러스터로 더 많은 시간동안 학습한 반면, DeepSeek‑V3는 H800 2,048개 GPU 클러스터를 사용하여, 자원 활용 측면에서도 효율적인 학습 전략을 입증했다.
결과적으로 DeepSeek‑V3는 자원 효율과 학습 최적화를 통한 혁신적 모델로, 앞으로의 AI 연구 및 실무에 큰 영감을 줄 것으로 기대된다.
댓글남기기