내 방식으로 Multi-Head Self-Attention 설명하기
Multi-Head Self-Attention을 내 방식대로 정리해보자.
Attention is all you need(Vaswani, Ashish, et al., 2017), 전설적인 논문이다.
Transformer 이후로 Language model은 Transformer 구조로 대동단결, Encoder stacking 형태의 BERT부터 Decoder stacking 형태의 현재의 ChatGPT까지 불과 10년이 안됐다.
Vision model도 Transformer 구조가 안쓰이는 곳이 이젠 거의 없고, 덕분에 vision model 전체적인 성능 향상과 multi-modality로 연결에서의 유연함까지 확보되었다.
처음 해당 논문을 공부하고나서 이해하고, 무수히 많은 프로젝트와 경진대회에 Transformer 구조를 응용하여 썼지만 정작 글로써 정리는 한번도 하지 않았다.
엄밀함과 정교함은 배제하고, 오직 내 방식대로 비약이 있더라도 비유로 개념만 한번 정리해보고자 한다.
사전 지식
- word embedding, query, key, value weight matrix 모두 learnable 하다.
- 벡터 간 내적(inner product)은 두 벡터 간의 유사도를 나타낸다.
- 두 벡터가 유사도가 높을 수록 내적 값이 크다(양수).
- 두 벡터의 유사도가 낮을 수록 내적 값이 작다(음수 가능).
- embedding vector가 matrix와의 연산을 거치더라도 정보는 보존된다.
- 가중 합(weighted sum)을 이용하여 더하고자 하는 변수들의 가중치(유사도 점수)를 반영하여 적용할 수 있다.
- 평균(unweighted sum)과 마찬가지로 가중 합에서 모든 가중치의 합은 1이다(계산의 일관성과 편리를 위해).
가중 합의 예시를 보자.
A의 시험 결과, 국어 점수 70점, 수학 점수 90점이라면 평균은 80점이다.
(70 + 90) / 2 = 80이라고 계산할 수도 있지만, 70 * 0.5 + 90 * 0.5 = 80으로 계산할 수도 있다.
여기서 0.5가 가중치다.
평균은 각각 가중치가 같으므로 가중치는 1 / n, 여기서는 1 / 2 = 0.5다.
가중 합은 어떨까?
A가 들어가고자 하는 학교는 국어 3 : 수학 7로 수학 점수를 더 중요하게 본다고 하자.
A의 점수는 70 * 0.3 + 90 * 0.7 = 84로 올랐다.
여기서 0.3, 0.7의 각 과목의 가중치이며, 가중치의 합은 1이다.
가중치의 합이 1이 아니고, 0.4, 0.8로 반영할 수 있지만, 어디는 가중치 합이 1이고, 다른 곳은 1.2고 다른 곳은 2면 명확한 비교가 되지 않는다.
또한, 평균도 가중치 합이 1이기 때문에, 평균과도 명확한 비교가 불가능하여 일관성을 위해 가중치 합을 보통 1로 맞춘다.
어텐션 연산은 구글 검색과 같다.
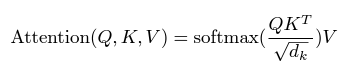
위 어텐션 수식이 뭘 의미하는걸까?
핵심만 보자면 query에 대한 key 각각의 유사도(softmax(qk^T))를 value에 곱하여 더한 것이다(가중치 합).
뭔 말이야…?
구글 검색에 빗대어 생각해보자.
query는 검색어다.
key는 검색 결과다.
value도 검색 결과다.
검색어(query)에 대한 검색 결과(key)의 유사도(softmax(qk^T))를 검색 결과(value)에 적용하여 유사도가 높은 순으로 검색 결과 상단에 정렬하는 거라 비유할 수 있다.
모델 안에서의 attention 연산도 위와 같다.
출발이 언어 모델인 만큼, 문장이 주어지면 문장 속 한 단어가 다른 단어(자신 포함)들과의 유사도를 구하고, 유사도를 가중치로 다른 단어들의 정보들을 가중 합한 것이다.
가령, “I am a boy.”에서 “I”가 query라면, “I”, “am”, “a”, “boy” 각각의 유사도를 구한 후 가중 합한다면, “I”에 대해 자신을 제외한다면, “boy”의 유사도(가중치)가 가장 높을 것이기에, attention score에는 “boy”의 정보가 가장 많이 반영됐을 것이다.
스칼라부터 시작해보자.
이하 query는 q, key는 k, value는 v로 표현

이어서 보면, 문장 속 단어 q 한개에 대해 문장의 모든 단어 k와 곱하여 유사도를 구한다(스칼라이므로, 내적은 단순 곱).
유사도 qk의 결과는 양수일 수도, 음수일 수도 있다.
음수를 곱해서 더하면 해당 유사도 정보가 오히려 손실되는데…?
가중 합을 하려면 가중치(qk)의 합이 1이 되어야 좋은데?
음수도 일괄적으로 양수로 바꾸고, 음수이면 작은 양수로, 양수이면 더 큰 양수이면 되겠다.
아 exponential을 취한 후 softmax 연산을 거치면 되겠구나!
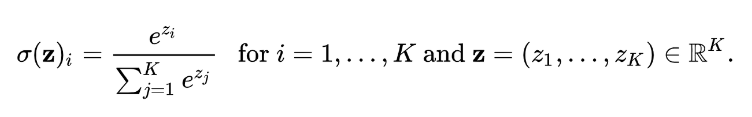
그래서 가중치는 softmax(qk)가 되겠네!
그러면 가중 합은 softmax(qk)v가 될 것이다.
벡터로 확장해보자.
문장 길이 = sequence length, 이하 seq으로 표현,
임베딩 벡터 차원 = dimension of model, 이하 dim으로 표현
하지만 “Attention is all you need.” 논문은 단어를 스칼라로 임베딩하지 않는다.
512 차원의 공간에 임베딩한다.
이후 768, 1024 등으로 점점 확장되었다.
왜 이렇게 임베딩할까?
단어를 여러 속성에 매핑할 수 있기 때문이다.
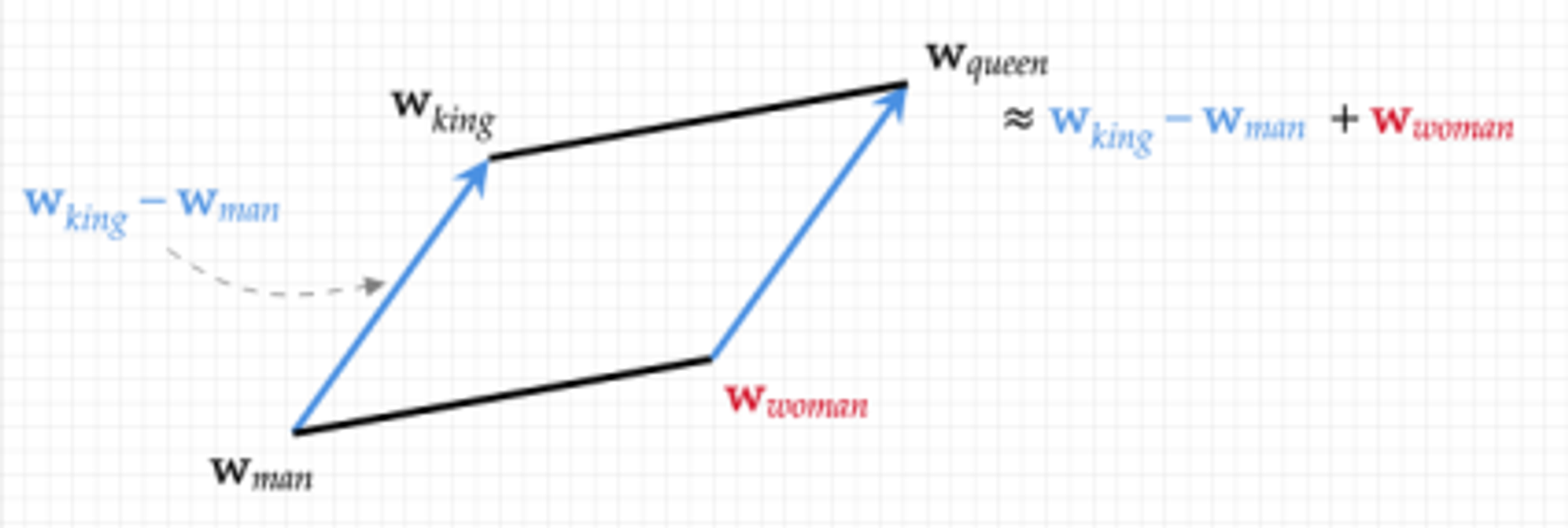
1개의 차원은 1개의 표현 가능한 속성이라고 말할 수 있다.
스칼라에 매핑한다는 것은 숫자 1개로 표현한다는 것이다.
물론 실수 전체의 범위를 가지는 스칼라지만, 1개의 차원은 곧 1개의 속성 안에서 표현되는 것이다.
위 그림과 같이 2차원이면 권력을 표현하는 수와 성별을 표현하는 수인 2개의 수(속성) 즉, 2차원 벡터로 표현되는 것이다.
수의 범위는 해당 속성 안에서 범위이지 속성의 확장은 아니다.
그렇기에 512, 768, 1024, … 점점 확장해나가며 단어가 많은 만큼 더 많은 속성으로 표현하고자 하는 것이다.
이 임베딩 weight은 learnable하기에, 단어의 다양성과 수가 확보된다면, 더욱 풍부하고 정교한 임베딩이 될 것이다.
그러면 벡터 연산도 생각해보자.
문장 속 단어 q 한개의 벡터에 대해 문장의 모든 단어 k 벡터와 내적하여 유사도를 구한다.
q와 k의 내적은 q와 k^T와의 행렬 곱과 같다.
내적 연산을 k 단어 한개씩 따로 하면 손해지!
q는 단어 1개이니 seq = 1, dim = n인 벡터라 하면, k는 seq = m, dim = n 행렬이다.
따라서, qk^T는 (1, n) * (n, m) = (1, m) shape의 연산이며, 결과의 의미는 단어 q(행 1)에 대한 단어 k들(m의 각 열)의 유사도 벡터가 된다.
그러므로, softmax(qk^T)v는 (1, m) * (m, n) = (1, n) shape의 연산이며, 결과의 의미는 검색어 단어 q(행 1)에 대한 검색 결과 문장 k, v의(열)의 유사도 가중 합이 된다.
그러면 n에서 각 열들이 가지는 의미는 뭘까?
다시 임베딩을 돌아가보면, 각 차원은 단어의 표현 가능한 속성이다.
그러므로, 열 1은 첫번째 임베딩 속성에서 유사도 가중 합, 열 2는 두번째, … , 열 n은 n번째 임베딩 속성에서 유사도 가중 합이다.
이제 행렬로 확장해야지.
생각해보면 q 단어 1개씩 연산하는 것도 손해다!
q를 단어 1개가 아니라, 모든 문장에 대해 한번에 행렬 곱으로 수행할 수 있다.
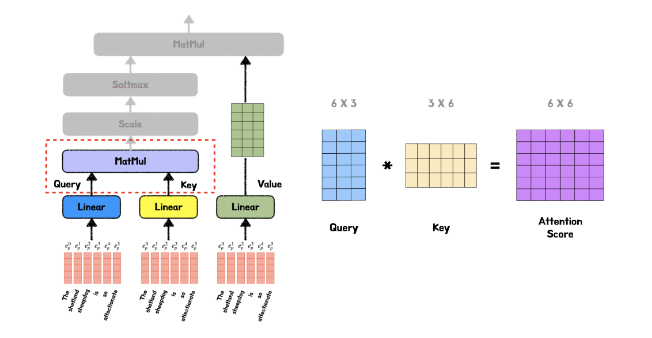
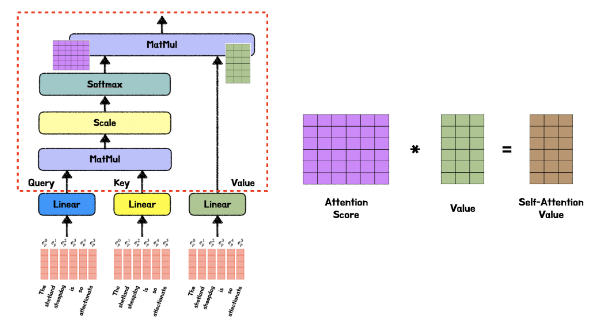
q는 이제 문장이니 seq = m, dim = n인 벡터라 하면, k는 seq = m, dim = n 행렬이다.
따라서, qk^T는 (m, n) * (n, m) = (m, m) shape의 연산이며, 결과의 의미는 단어 q들(행)에 대한 단어 k들(열)의 유사도 행렬이 된다.
행 m은 q, 열 m은 k가 된다.
가령 (2, 3)은 q의 2번째 단어에 대한 k의 3번째 단어의 유사도다.
(여기서 알 수 있는 건, 유사도는 k의 유사도라는 것이다.)
그러므로, softmax(qk^T)v는 (m, m) * (m, n) = (m, n) shape의 연산이며, 결과의 의미는 검색어 문장 q(행)에 대한 검색 결과 문장k, v의(열)의 유사도 가중 합이 된다.
그런데 잠깐, k와 v는 검색 결과이니 seq, dim이 같은 건 맞는데 너무나도 당연하게 q의 seq, dim을 k, v와 같게 가정했네?
Self-Attention
q의 seq, dim을 k, v와 같이 가정한 것은 해당 attention은 self-attention, 즉 자기 자신(동일 문장)과의 attention 연산이기 때문이다.
본 논문의 근본적인 목적은 문장 안에서 단어들의 서로 간의 관계를 파악하여 단어들의 의미를 구하고 다음 단어 혹은 문장을 예측하는 것이다.
근데 위 연산대로라면 문장에서 단어의 순서를 바꿔도 attention 결과 행렬 요소의 각 위치만 바뀔 뿐 값이 차이가 나지 않는데?
문장에서 단어의 순서를 바꾸면 의미가 달라지는 경우가 많은데?
“인도 카레 전문점 건너편 레스토랑”과 “카레 전문점 인도 건너편 레스토랑”은 단어 순서만 바꿔도 그 의미가 전혀 달라지는데?
Positional Encoding
q의 seq, dim을 k, v와 같이 가정한 것은 해당 attention은 self-attention, 즉 자기 자신(동일 문장)과의 attention 연산이기 때문이다.
그래서 positional encoding이 필요하다.
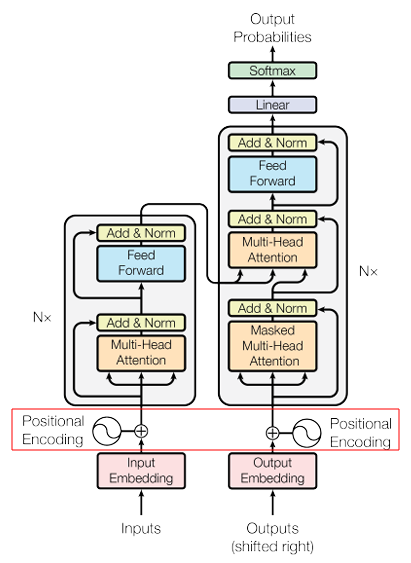
여기, 임베딩 벡터들이 attention 연산을 거치기 전에 positional encoding을 거친다.
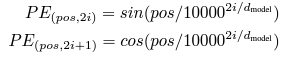
positional encoding이란, 간단히 말해 임베딩 문장 seq에 따라 주기화되고 각 주기에 따라 값이 미세하게 변하는 아주 작은 숫자들을 벡터에 더해 순서 정보를 추가하는 것이다.
그런데 문장 속 단어 순서 정보는 그렇다 치고, 동음이의어는 어떻게 파악하지?
“인도”가 나라인지, 보행자 통로인지 어떻게 구분할까?
다시 Self-Attention, 여러번 Self-Attention!
그래서! self-attention을 하는 것이다.
동음이의어를 구분하는 방법은 해당 단어의 앞의 단어들과 뒤의 단어들을 통해 맥락을 파악하는 것이다.
Self-attention은? 같은 문장에서 단어들끼리의 유사도 가중 합이다.
그렇다면 self-attention 결과 행렬은 더 이상 단순한 단어들이 아니라, 앞 뒤 맥락 정보가 포함된 정보된 단어인 것이다.
예컨대, “인도”는 더이상 “인도”가 아니라 “카레” 단어의 정보가 맥락에 반영된 “인도”인 것이다.
그러면 self-attention 연산을 여러번 수행하면, 정보는 보존되니 맥락 정보가 더욱 깊어지겠네?
첫번째 attention 연산 이후 두번째 attention은 단어 간 attention이 아니라 attention score가 적용된 즉, 주변 단어들의 정보가 포함된 단어들 간의 attention인 것이다.
그래서, Transformer는 크게 Multi-Head Self-Attention, Feed Forward로 구성된 블록을 여러개 쌓아서 self-attention 연산을 여러번 수행하는 것이다.
Multi-Head? 대가리가 여러개인가?
그러면 Self-Attention이면 Self-Attention이지, Multi-Head Self-Attention은 무엇인가?
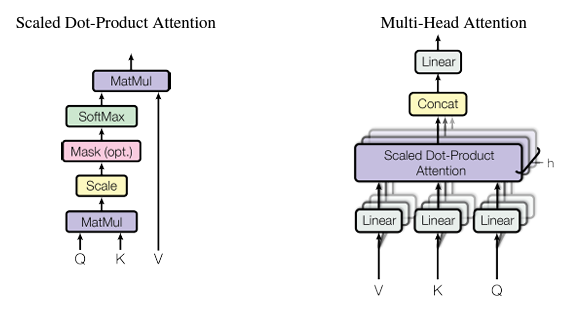
간단히 말하자면, Self-Attention 연산을 여러개의 Head에서 병렬로 수행한 후 합치는 것이다.
왜 GPU VRAM 아깝게 병렬로 여러번 수행할까?
Multi-Head에서 각각의 weight matrix 역시 모두 learnable하다.
그렇다는 것은 embedding 각각의 차원이 단어의 다른 속성을 표현하듯, 각각의 head에서 다른 head들에 비해 단어의 특정 feature들을 더욱 잘 학습할 수 있다는 뜻이다.
마치 같은 layer 내에서도 여러개의 convolution filter들이 다른 feature를 학습하듯 각각의 head 또한 그런데, convolution 연산과 달리, 매우 안정적으로 input shape과 output shape을 동일하게 유지해서 마치 벽돌 쌓듯 transformer block을 쌓아서 모델의 크기를 키우기 좋다.
잠깐, head가 여러개인데 shape이 유지된다는 말을 자연스럽게 하고 넘어가네?
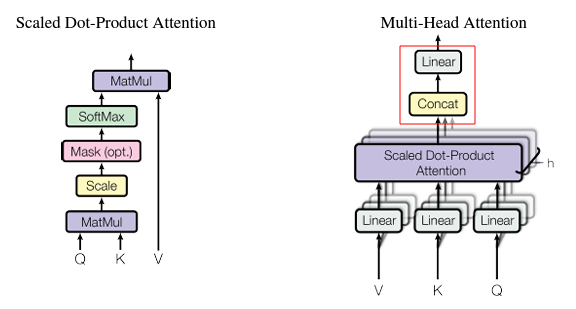
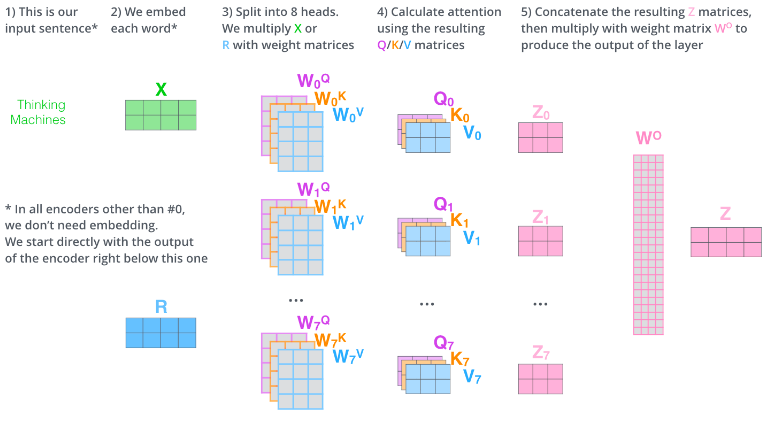
그거야 여러개의 head에서 나온 attention score들을 일렬로 연결하여 위와 같이 learnable한 weight matrix와의 matmul 연산으로 다시 shape을 유지해주기 때문이지.
weight을 통과해도 정보는 유지되니까.
오히려 각 head에서 학습된 다른 feature들의 정보가 마치 self-attention 때 처럼 합쳐지니까.
이게 Transformer 구조의 강점인 유연함이고, 이 유연함 덕분에 모델의 크기를 안정적으로 키울 수 있는 것이다.
Convolution의 연산의 경우 group을 설정해주지 않는 한, convolution filter가 직전 layer의 모든 channel들을 돌며 연산 후 합치는데, Transformer처럼 convolution 후 channel을 쭉 펴서 weight matrix와 matmul하면 channel 정보를 잃어버린다.
근본이 평면 연산인 것을 병렬로 한 후 다시 평면으로 합치는 것과 channel에 기반한 연산을 평면으로 펴버리는 것은 다르다.
Masked Multi-Head Attention?
아직 masking 한발 남았다…
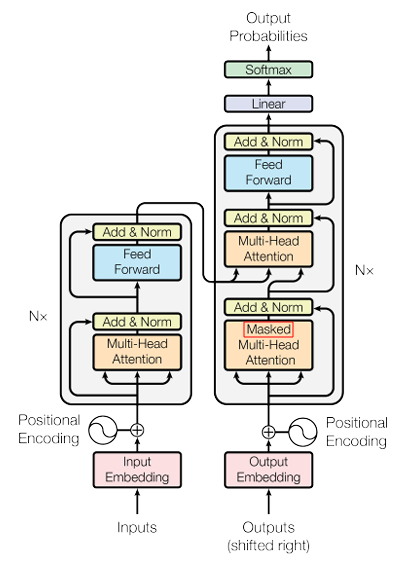
위 그림을 보면 Decoder block에 Masked Multi-Head Self-Attention이 있네…?
Masking이 뭔데?
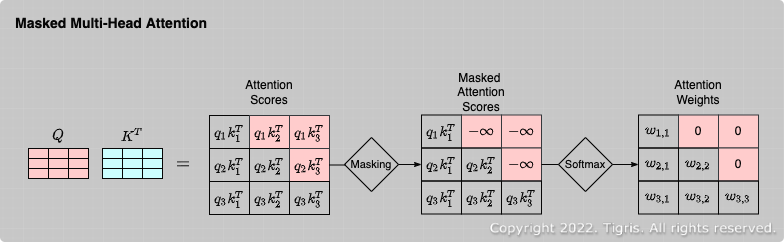
Masking은 말 그대로 임베딩 벡터들을 masking하여 모델이 못보게 하는 것이다.
Masking 방법은 간단하다. 본래의 값 대신, 엄청나게 큰 음수 값을 주면 내적 후 exponential을 취하면 0에 근사한 값이 나와서 attention score에 반영이 되지 않는다.
Masking은 그래서 왜 할까?
Decoder block에서의 역할은 문장에서 다음 단어의 예측이다.
특정 시점에서 다음 단어를 예측해야하는데 다음 단어의 정보가 포함되어 있으면 답지 보고 맞추는 것과 무엇이 다른가?
그래서 masking을 통해 미래 단어의 정보를 가리는 것이다.
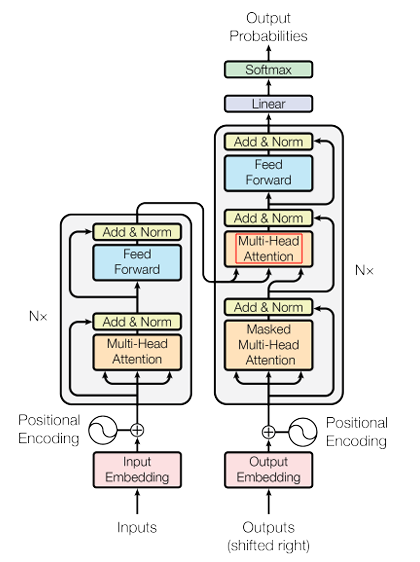
그래서 위 그림을 보면 Masked Multi-Head Attention 연산 후 오는 attention의 명칭은 “Self”가 빠진 Multi-Head Attention이다.
Encoder block에서 Multi-Head Self-Attention을 거친 맥락 정보들을 q와 k에, Decoder block에서 Masked Multi-Head Attention을 거친 정보들을 v에 적용하기 때문에 더이상 “Self”가 아닌 것이다.
Multi-Head Self-Attention을 거쳐 맥락 정보가 담긴 q와 k의 유사도 가중치(softmax(qk^T))를 이용하여 Masked Multi-Head Attention을 거친 v에 가중 합하여 다음 단어를 예측한다.
Transformer의 Decoder block의 이러한 특성으로 인해 다음 단어, 다음 문장, 다음 문단… 즉 생성형 AI라는 특징을 가진다.
Decoder block만을 쌓은 것이 GPT의 핵심 구조이며, GPT 1, GPT 2에서는 큰 각광받지 못하다가 GPT 3에서 Transformer의 모델 크기 확장의 유연함을 이용하여 정말 큰 모델을 만들고 엄청난 데이터를 학습시켜서 괄목할만한 퍼포먼스를 보여줬다.
아무래도 masking 때문에 정보가 가려지다보니, 더 큰 모델, 더 많은 데이터가 되고나서야 빛을 발한 것이다.
뿐만 아니라, BERT 등의 Transformer의 Encoder block만을 쌓은 모델에서도 [MASK] 토큰을 이용한 Masked Language Model로 구성하여 기존 masking을 응용한 모습을 보여줬다.
결국 궁금한건 내가 했던 말이 아니라 네가 하고싶은 말이니까!
후기
연구자의 생각과 흐름을 내 방식대로 따라가보고자 Multi-Head Self-Attention을 정리해봤다.
Scaled-dot product, Position-Wise Feed-Forward, Residual Block, Layer Normalization(최근 RMS Layer Norm)과 코드 등 디테일들을 챙길 틈도 없이 주요 개념들을 비유만하는데도 글이 훌쩍 길어졌다.
그러나 정교한 의미, 정확한 연산과 구조, 디테일은 훨씬 정리 잘하시는 분들이 시각 자료까지 곁들인 정보들이 넘치니 북마크로 만족한다.
내 방식대로 핵심 의미를 잃어버리지 않고자 정리해본 것인데, 재미있다.
개념을 이해할 때 숲을 이해하는 것이 중요하다.
그런데 일반적인 발전 순서는 [현상의 발견 혹은 개념의 발명] -> [다른 것들과의 공통점 발견] -> [일반화, 추상화하여 엄밀한 정의] -> [개념의 확장]이다.
잘 이해하기 위해서는 똑같은 순서로 따라가보는 것도 괜찮은 것 같다.
먼저 발견하고, 다른 숲의 비슷한 나무들과 비교하고, 정의를 내리고, 확장해보면 재미있다.
Reference
Attention is all you need paper
Multi-Head Self-Attention figure 출처1
댓글남기기