MiniMax Lightning Attention Review
MiniMax Lightning Attention Review
👉🏻논문 링크
최근 AI 모델 스케일링과 long context 처리에 대한 관심이 높아짐에 따라, MiniMax-01을 주목해볼 필요가 있다. 본 리뷰에서는 MiniMax-01 전체 모델의 개요를 소개하되, 특히 Lightning Attention 기술에 집중한다. 특히 세부 구조, 효율성, 그리고 기존의 Softmax 및 Linear Attention과의 차별점을 자세히 살펴본다.
Model and Data Overview
모델에 대해서는 LLM과 VLM을 모두 간략히 정리하되, 이후 LLM 위주로 살펴본다.
Model Overview
MiniMax-01 시리즈는 두 가지 모델로 구성된다.
- MiniMax-Text-01 (LLM)
- 총 파라미터: 456B
- MoE 전문가: 32개
- 토큰당 활성화 파라미터: 45.9B
- 학습 컨텍스트 창: 최대 1M tokens
- 추론 컨텍스트 창: 최대 4M tokens
- MiniMax-VL-01 (VLM)
- 학습 데이터: 512B vision-language tokens
- text model backbone에 추가 모듈을 도입하여 멀티모달 입력 처리
Data Overview
-
LLM(MiniMax-Text-01):
-
주요 데이터셋: CommonCrawl, Wikipedia, BookCorpus, 뉴스 데이터 등
- 토큰 규모: 약 300B 이상의 토큰
- 여러 소스의 대규모 코퍼스를 통합하여 사용
-
-
VLM(MiniMax-VL-01):
- 주요 데이터셋: COCO, Visual Genome, 그리고 자체 구축 image-text pair data
- 토큰 규모: 총 512B vision-language tokens
Hyper-Parameters
MiniMax-01의 학습은 일반적인 LLM 학습 과정과 같이 Pre-training과 Post-training (SFT, RL) 단계로 구분된다.
Pre-training
-
Data Construction:
- 텍스트 모델은 위에서 언급한 대규모 웹 크롤링, 백과사전, 서적, 뉴스 데이터 등에서 약 300B tokens를 사용한다.
- 컨텍스트 창은 최대 1M tokens까지 확장하여 모델이 장문 내 장기 의존성을 학습할 수 있도록 구성한다.
-
Hyper-Parameters:
-
Optimizer:
AdamW
- $β1=0.9$, $β1=0.9$, $β2=0.98$
- Weight Decay = $0.01$
-
Scheduler:
- Initial Learning Rate: $1×10^{−4}$
- 초기 10k steps 동안 linear warmup 진행
- 이후 cosine decay으로 총 500k steps에 걸쳐 학습
-
Batch size:
- 개별 GPU 당 2048 sequence
- 분산 학습 환경에서는 1024대의 GPU를 활용
-
-
학습 전략:
- 최적화된 병렬 전략과 통신–연산 오버랩 기법을 통해 MoE와 Lightning Attention 모듈 모두에서 높은 효율성을 확보
Post-training
- 목적: 다운스트림 작업(예: 요약, 번역 등)에 최적화
SFT
- Data Construction:
- 고품질 인간 작성 데이터셋을 활용해 모델의 응답 품질 개선
- 다만, 구체적인 데이터 소스와 토큰 수, 구성에 관한 세부 정보는 논문에 명시되어 있지 않음
- Hyper-Parameters:
- SFT 전용 LR, Batch size 등은 논문에 구체적으로 제시되지 않았으나, Pre-training과 유사한 AdamW 기반의 설정을 변형해 사용한 것으로 추정
RL
- Reward Model:
- 사용자 피드백 또는 사전 정의된 평가 지표를 기반으로 reward model을 적용
- 구체적인 reward model의 구조, 사용 데이터, 강화 기법 등에 대한 세부 정보는 논문에 제공되지 않음
- Hyper-Parameters:
- 구체적으로 명시되어 있지 않음
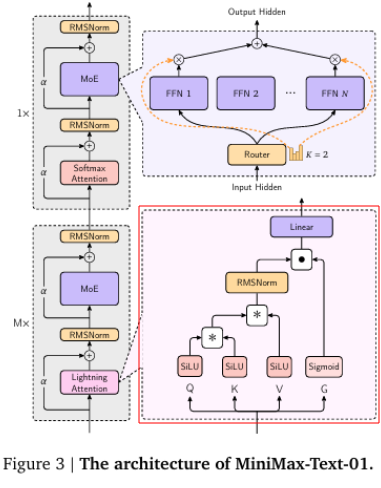
Lightning Attention
MiniMax-01의 핵심 혁신은 Lightning Attention에 있다. 이 섹션에서는 기존의 Softmax Attention과 Linear Attention의 한계를 극복하기 위한 Lightning Attention의 구체적인 구조와 효율성을 자세히 분석한다.
📌 Lightning Attention Architecture
Softmax Attention
- 수식:
- $\text{Attention}(Q, K, V) = \text{softmax}\Bigl(\frac{QK^\top}{\sqrt{d}}\Bigr)V$
- 계산 복잡도:
- $O(n^2 \cdot d)$
- $n$: sequence length, $d$: feature dimension
- Long Context 처리 시 메모리와 연산 비용이 급격히 증가
- $O(n^2 \cdot d)$
Linear Attention
- 핵심 아이디어:
- “Right product kernel trick”을 활용하여 Attention 연산의 quadratic 복잡도를 선형 복잡도로 변환
- 수식 변환:
- 기존 NormAttention: $O = \text{Norm}((QK^\top)V)$
- 오른쪽 행렬 곱셈을 이용한 변형: $O = \text{Norm}(Q(K^\top V))$
- 계산 복잡도:
- $O(nd^2)$
- 장점: Recurrent prediction에 적합하며, $K^\top V$를 미리 계산하여 반복 계산을 줄임
- 단점: Causal language modeling에서는 오른쪽 곱셈의 효율성이 떨어지고, cumsum 연산이 필요하여 병렬화에 한계가 있음
Lightning Attention
Lightning Attention은 기존 linear attention의 병목인 느린 cumsum 연산을 해결하기 위해 제안된 I/O-aware 최적화 기법이다.
- 핵심 개선점:
- Tiling 기법 도입:
- Q, K, V 행렬을 $B \times d$ 크기의 블록으로 분할하여 계산
- Intra-block & Inter-block 분할:
- Intra-block 계산:
- 상대적으로 작은 블록 내에서는 left product attention을 사용하여 빠른 계산을 수행
- 수식 예시: $O_{\text{intra}} = \Bigl[(QK^\top) \odot M\Bigr]V$ 여기서 $M_{ts}=1$ if $t \ge s$
- Inter-block 계산:
- 블록 간 누적된 값을 활용하는 right product attention을 사용
- 재귀적 업데이트: $kv_0 = 0,\quad kv_t = kv_{t-1} + k_t v_t^\top,\quad o_t^\top = q_t^\top kv_t$
- Intra-block 계산:
- Tiling 기법 도입:
- Tiling을 통한 최종 연산 복잡도:
- 최종 시간 복잡도는 $O(nd^2 + nBd)$로, $B$는 블록 사이즈
- 실제 실험에서는 $n = 10^6$, $d = 1024$ 조건에서 전통적 softmax attention 대비 연산량이 약 1000배 절감 효과를 보임
- Hybrid 구조 내 Lightning Attention 적용:
- 매 8 레이어마다 초기 7 레이어에 Lightning Attention을 적용하여, 글로벌(long-range) 정보를 효율적으로 집약
- 나머지 1 레이어는 전통적 softmax attention을 사용해 지역적 세부 표현을 보완
- Ablation study 결과, 이러한 Hybrid 구조가 모델 성능과 연산 효율성 측면에서 최적의 균형을 이루는 것으로 나타남
요약:
- Softmax Attention: $O(n^2 \cdot d)$ → 긴 시퀀스에 부적합
- Linear Attention: $O(nd^2)$ → cumsum 연산 병목 존재
- Lightning Attention: $O(nd^2 + nBd)$ → tiling 기법과 intra-/inter-block 분할을 통해 cumsum 병목 제거, 효율적 병렬 처리 및 I/O 최적화 달성
Contributions
- 컨텍스트 확장:
- MiniMax-01 시리즈는 기존 모델 대비 20~32배 긴 extremely long context를 지원할 뿐만 아니라 성능 또한 뛰어남
- 연산 및 메모리 효율성:
- Lightning Attention 도입으로 only softmax attention에 비해 연산량이 극적으로 줄어들었으며, 1M 토큰 처리 시 약 1000배 절감 효과가 있음
- 실험 결과:
- MiniMax-01은 최신 모델(GPT-4o, Claude-3.5-Sonnet)과 동등한 성능을 보이며, 특히 초장문 처리 및 긴 컨텍스트 모델링에서 확연한 우위를 보임
후기
MiniMax-01은 Lightning Attention을 핵심 혁신으로, 초대형 모델의 확장성과 초장문 처리 문제를 효과적으로 해결한 사례다. 특히, 기존 기술의 한계를 체계적으로 보완한 점에서, 향후 다양한 모달리티와 다운스트림 작업에 응용될 수 있는 잠재력이 크다. Lightning Attention의 구체적인 설계와 효율성을 볼 때, model scaling에서 적용 및 발전의 여지가 충분하다.
댓글남기기