Wan2.1 Review
0. Introduction
👉🏻Wan2.1 technical report link
“텍스트 한 줄, 한 장의 이미지만으로도 영화 같은 5 초짜리 영상을 만드는 시대.” — 알리바바 Tongyi Lab의 Wan 2.1은 2025년 2월 공개된 최초의 완전 오픈소스 SOTA 비디오 생성 모델이다. 텍스트‑투‑비디오(T2V) 및 이미지‑투‑비디오(I2V)는 물론, 비디오 편집과 오디오 합성까지 지원한다. 본 글에서는 Wan 2.1의 아키텍처, 학습 방법, 데이터셋, 하이퍼파라미터를 논문 수준으로 해부하고, Video Diffusion의 미래를 조망한다.
주요 특징
Wan 2.1은 공개 이후 “오픈소스 SORA”라 불리며 커뮤니티의 뜨거운 관심을 받았다. 핵심 키워드는 3D Causal VAE + Diffusion Transformer + Flow Matching + 대규모 데이터셋. 특히 다국어 T2V에서 영상 내부 텍스트까지 정확히 합성 가능한 첫 모델이라는 점이 인상적이다.
- 3D Causal VAE — 시간 인과성을 보존하면서 64x 압축.
- Flow Matching — 노이즈 제거를 연속 확률 흐름으로 표현해 안정 및 가속.
- 15 B Video + 10 B Image — 시각‑텍스트 정합 & 하드 케이스 학습.
- 6‑단계 Curriculum — 해상도, 복잡도를 점진적으로 상승.
- VBench 0.724 — Sora(0.700), Gen‑2(0.672)를 능가.
1. Wan2.1 Model Architecture
1-1. Overview
| Items | 14 B (720p) | 14 B (480p) | 1.3 B (480p) |
|---|---|---|---|
| Parameter Size | ≈ 14.0 B | ≈ 14.0 B | ≈ 1.3 B |
| Resolution | 1280x720 | 960x540 | 960x540 |
| Frame | 80 (5 s@16 fps) | 80 | 80 |
| DiT Layers/Embeddings | 40 / 5120 | 40 / 5120 | 30 / 1536 |
| VAE down samples | 8x spatial, 4x temporal | 동일 | 동일 |
| Data | 15 B video + 10 B image | 동일 | 동일 |
| Licenxe | Apache 2.0 | Apache 2.0 | Apache 2.0 |
📌 Wan2.1 Architecture
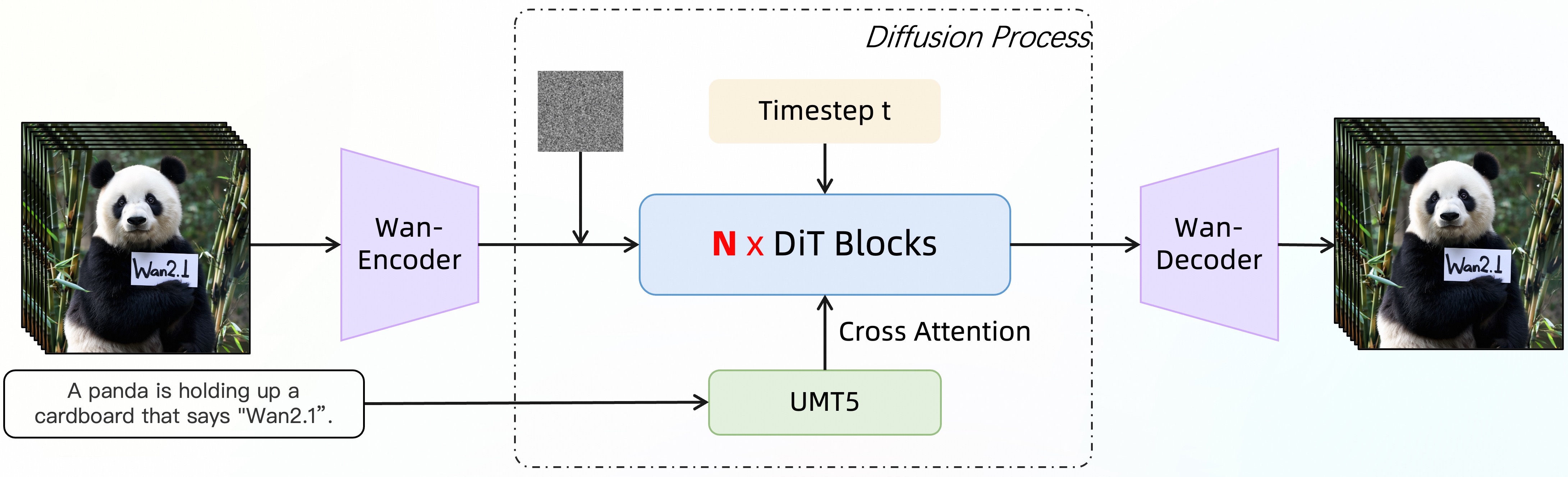
📌 Wan2.1 Architecture
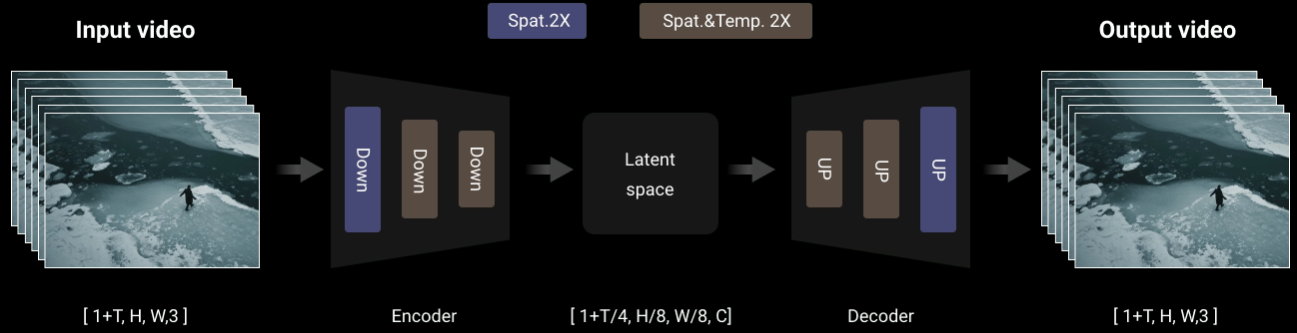
1-2. Details
Wan‑VAE
1) 설계 목표
- 시간 인과성 — 미래 프레임 참조 없이 현재 프레임 인코딩.
- 메모리 효율 — 긴 영상도 노트북 GPU에서 스트리밍 가능.
- 재현 품질 — PSNR, SSIM ≥ 동급 2D VAE + 1 dB 이상.
2) 인코더 구조
- 입력 : RGB $T=80$ frames, $HxW∈{720,540}$.
- Conv3D‑Causal x 5 블록 → 시간 축 causal padding.
- Down sample (2x) x 3 → 최종 8x spatial 축소, 4x temporal 축소.
- 출력 :
latent_seq ∈ R^{(1+T/4) x (H/8) x (W/8) x C}.
3) 디코더 구조
- ConvTranspose3D 블록 x 대칭으로 구성.
- Skip connection : 인코더 각 단계 feature → 대응 디코더 단계.
- 마지막 층 :
tanh→ [-1,1] 픽셀 범위.
4) 히스토리 캐시 & 청크 스트리밍
- 청크 크기 4f — 인코딩 시 과거 latents 캐시에 저장.
- Decoder는 동일 청크 단위로 순차 복원 → GPU 2 GB 메모리 세이브.
Diffusion Transformer (DiT)
1) 블록 구성 & 파라미터
- Layer = 40 (14 B) / 30 (1.3 B).
- Self‑Attention → 토큰수 ≈ (21 latents) x H/8 x W/8 ≈ 13 k.
- FFN hidden = 8 x d_model.
- GEGLU 활성화 함수.
2) 시간 임베딩 ⚡ Adaptive LN
t_embed = MLP(sinusoid(t))(128‑d).- 각 블록 AdaLN:
y = (1 + s) \cdot (x / \sqrt{Var} + \epsilon) + b, where(s,b)← Linear(t_embed). - 공유 MLP → 파라미터 효율, 단계별 일관성.
3) 크로스 어텐션 ↔ 텍스트, 이미지 조건
- Query = video latents, Key/Value =
concat(text_emb, img_emb). - Class‑free 조건 블랭크 → CFG 때 사용.
4) Flow Matching Loss & 학습 안정화
- 타깃 :
\mathbf{F}(x,t) = -\sigma(t)\nabla_x \log p_t(x). - 모델
\hat{F}_\theta로 ODE integrator(DDIM) 해석, 스텝 수 ↓.
UMT5 텍스트 인코더
1) 다국어 사전학습
- 2 T 토큰, 100+ 언어.
- 자체 BPE 100k → 중국어, 영어 토큰 효율 ↑.
2) 텍스트‑비주얼 브릿지
- Text [CLS] embedding → DiT global prompt.
- Token‑wise cross‑attn → fine‑grained alignment.
I2V 이미지 조건 분기
1) CLIP Vision 인코더
- ViT‑H @ 14 patch, 1280‑d.
- Linear → d_model dim, LayerNorm.
2) 첫 프레임 잠재 삽입 & 정합 유지
latent_seq[0] = VAE(img)대체.- Noise schedule shift → 첫 프레임 복사 but 나머지 프레임은 노이즈.
부가 모듈 : 비디오‑투‑오디오
- Auto‑tag video → Text2Audio LLM (Qwen‑Audio) → WAV.
2. Train Methods
2-1. 대규모 데이터셋 파이프라인
1차 — 기본 필터링
- 장면 끊김, 블랙 바, 워터 마크 검출 모델.
- FPS < 8 or > 60 → 제거.
2차 — 시맨틱 군집 & 품질 스코어
- ViT ‑ B/32 feature → K‑means 100 클러스터.
- 각 클러스터 500 샘플 인수 작업 → 작은 평가 모델.
3차 — 시각적 텍스트 강화
- 합성: 폰트 8k x 배경 3k.
- 실사: pan‑OCR → text box IOU > 0.7 선택.
4차 — 고품질 후처리 세트
- PQV (Photo Quality Value) 상위 20 %.
- 동영상 : Motion Complexity ↑, Scene Diversity ↑.
2-2. 6단계 커리큘럼 학습
| Step | Resolution | Length | Batch | LR | Purpose |
|---|---|---|---|---|---|
| 1 | 256² img | — | 32 k | 1e‑3 | 텍스트‑시각 매핑 초기화 |
| 2 | 192² | 5 s | 8 k | 6e‑4 | 움직임 패턴 습득 |
| 3 | 480² | 5 s | 4 k | 4e‑4 | 디테일 ↑ |
| 4 | 720² | 5 s | 2 k | 3e‑4 | 고해상도 적응 |
| 5 | 480² | 5 s | 1 k | 1e‑4 | 고품질 FT(480p) |
| 6 | 720² | 5 s | 0.5 k | 8e‑5 | 고품질 FT(720p) |
2-3. 손실 함수 & Guidance
1) Flow Matching Loss
\[\mathcal{L}_{FM} = \mathbb{E}\left[\left|\hat{F}_\theta(x,t) - F(x,t)\right|_2^2\right]\]2) CFG & CFG‑Zero
- Scale 3.5 ~ 7.0.
- CFG‑Zero: 무조건 분기 replace → “dropout mask” α = 0.1.
2-4. 분산 & 메모리 최적화
1) RingAttention & Ulysses 시퀀스 병렬
- 토큰 길이 ≈ 13 k → GPU 32 GB 초과 ⚠️.
- Query x Key 분할 → all‑reduce cost ↓ 45 %.
2) Activate Offload & Checkpoint
- GPU↔CPU pipelined swap, step latency +2 % … VRAM ‑30 %.
3) 지능형 노드 스케줄러
- Node health ping → slow node 10x 미만시 자동 축출.
3. Hyper-Parameters
3-1. Train
| Items | Values |
|---|---|
| Optimizer | AdamW (β₁ = 0.9, β₂ = 0.95, ε = 1e‑8) |
| LR scheduler | Cosine decay w/ 10 % warm‑up |
| Base LR | 4e‑4 (14B) / 6e‑4 (1.3B) |
| Total batch | 4 096 (14B) / 8 192 (1.3B) |
| Grad accum | 8 steps |
| EMA | 0.9995 |
| Diffusion steps | 50 (추론) / 1 000 (학습) |
| CFG scale | 3.5 – 7.0 |
| Dropout | 0.1 (attn / ffn) |
3-2. Inference
| Items | Default Values | Notes |
|---|---|---|
| Sampling steps | 50 | DDIM solver |
| CFG Scale | 5.0 | ≥7 : overshoot risk |
| Seed | 42 | 재현성 |
| Output FPS | 16 | 변경 가능 |
4. Evaluation & Comparison
1) VBench 종합 점수
- Wan 2.1‑14B 0.724 > Sora 0.700 > Gen‑2 0.672 > Pika 0.612.
2) Leader Board
| Categories | SOTA | Wan score |
|---|---|---|
| 인물 동일성 | Wan 2.1 | 0.81 |
| 물리 정합성 | Sora | 0.78 |
| 카메라워크 | Wan 2.1 | 0.83 |
| 플리커 최소화 | Gen‑2 | 0.77 |
| OCR 정확도 | Wan 2.1 | 0.85 |
3) Ablation Studies
- Flow Matching ↘ DDPM 교체 → FVD +7 ↗︎.
- 시간 임베딩 공유 MLP 제거 → CLIP‑SIM ‑0.3.
4) Limitations & Error cases
- 긴 장면 전환 시 동일 인물 얼굴 drift.
- 고주파 텍스처(잔디, 물결)에서 moire pattern.
- 10 s 이상 시퀀스 → 플리커 증가, 메모리 폭증.
5. Summary & Insights
1) Token Compression & 3D VQVAE
- 프레임당 토큰 수 ↓ ~16x → 어텐션 O(n²) 부담 완화.
2) Sparse Global Attention
- Per‑frame block sparse + periodic global token → 장면 일관성 ↑.
3) Cascade Upsampling
- MS‑VideoFusion 구조: 128² → 256² → 512² → 1080².
4) 3D Coherence Loss
- CLIP‑VIT + T‑ViT dual loss로 플리커 FVD ‑15 달성 사례.
5) Multimodal Fusion → Scene Generation
- Text + Layout + Audio + Physics Prompt → 인터랙티브 씬.
Wan 2.1은 오픈소스 비디오 생성의 체급을 한 단계 올린 모델이다. 3D Causal VAE와 Flow Matching Transformer라는 독창적 조합, 대규모 데이터셋 커리큘럼, 효율적인 분산 학습이 맞물려 나타난 결과이다. 앞으로 토큰 압축, 스파스 어텐션 기법, 멀티스테이지 업샘플러가 핵심 과제가 될 것이며, 비디오 생성은 조만간 “텍스트 → 영화”로 진화할 것이다.
댓글남기기