DDP보다 더 발전된 전략 탐색
FSDP, DeepSpeed
DDP(Distributed Data Parallel)을 현재 서버에서 잘 활용하던 중, 문득 궁금해졌다.
다음 진행될 연구에서 대규모 모델을 활용할 예정인데 multi-GPU machine이어도, model 전체가 GPU 1장에 올라가지 않으면 machine이 DDP로도 소용이 없네?
결국 data parallel이 아닌, model parallel을 활용할 운명이구나.
DDP 조사와 프로젝트 리팩토링을 한지 얼마 지나지 않아, 설연휴 동안 model parallelism에 대해 조사하고 현재 프로젝트에 적용해봤다.
FSDP(Fully Sharded Data Parallel)
👉🏻참고 링크 - PyTorch 블로그의 FSDP 소개
👉🏻참고 링크 - PyTorch Lightning에서 FSDP 사용
FSDP란?
DDP에서는 model parameters, gradients, optimizer states 등의 모델 관련 정보들을 GPU에 저장하고 업데이트한다.
그런데 이것들이 용량을 상당히 차지한단 말이지?
그렇다면, 모델 관련 정보들을 분산시켜서 서로 다른 GPU에 저장하고, 필요할 때만 GPU간 통신으로 관련 정보를 가진 GPU가 그렇지 않은 각 GPU에 전달해주면 되지 않을까?
GPU간 통신 비용이 증가하겠지만, 큰 모델의 경우 당장에 모델 전체가 GPU 1장에 올라가지 않는걸?
그래서 FSDP! Fully Sharded Data Parallel, 즉 __데이터 batch 뿐만 아니라 모델 정보까지 모두 여러 GPU에 쪼개버리는 것__이다.
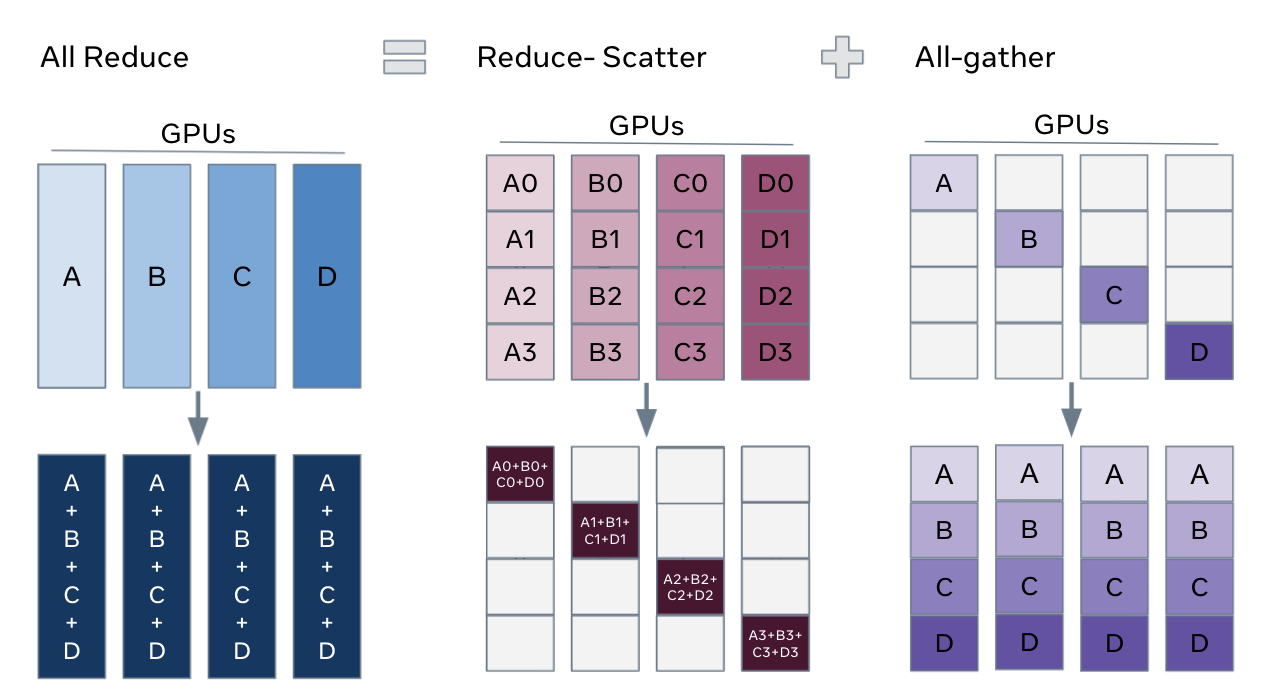
모델을 분리, 저장하여 위와 같이 연산 단계에서 사용한다(NCCL 연산 소개 링크 참고).
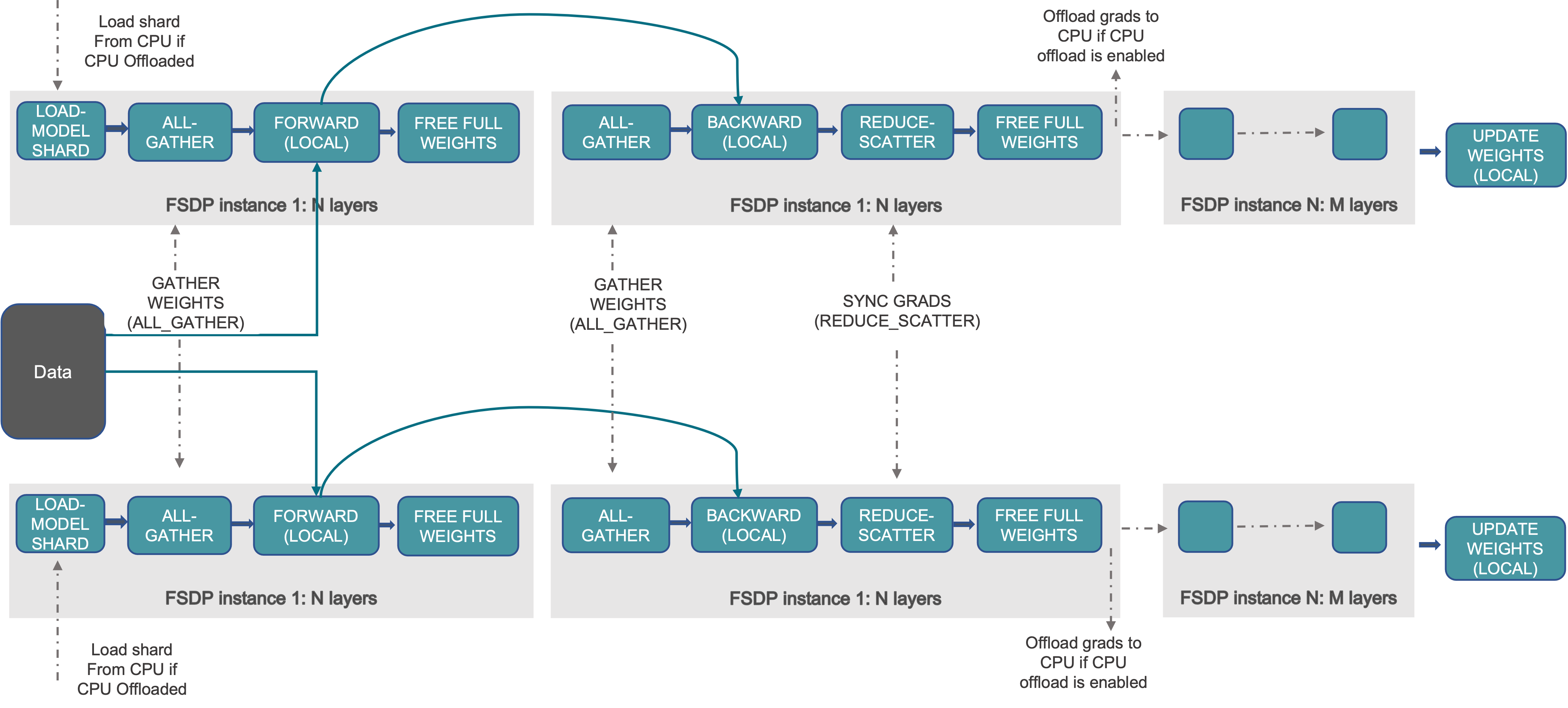
FSDP의 전체 flow
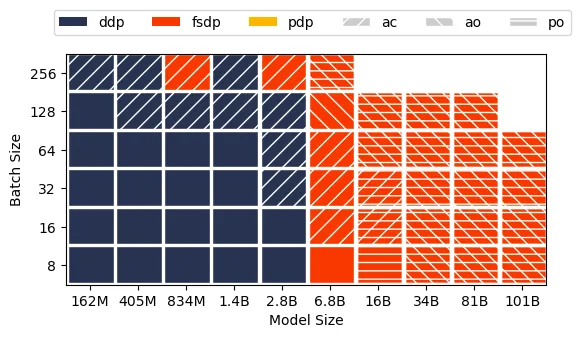
A100×8, 600GB/s NVLink 기준 model, batch size에 따른 DDP or FSDP 추천
사용 방법(PyTorch Lightning)
PyTorch Lightning에서는 Trainer의 strategy=”fsdp”로 간단히 적용할 수 있다(버전 2.0 이상).
lightning.pytorch.strategies import FSDPStrategy
해당 import 후, strategy 옵션을 조정할 수 있다.
버전 1.7 이상, 2.0 미만에는 stategy=”fsdp_native”로 입력해야 한다.
from pytorch_lightning.strategies import DDPFullyShardedNativeStrategy
마찬가지로 해당 import 후, strategy 옵션을 조정할 수 있다.
프로젝트에서는 아직 시험 단계이고, DDP, FSDP, DeepSpeed를 모두 hydra-core 관리 하에 간단히 이용하고 싶어서 옵션을 상세 조정하지는 않았다.
FSDP의 경우, DDP와 마찬가지로 설정한 batch size는 machine 전체의 batch size가 아닌, 각 process(GPU 1장)에 대한 batch size다.
DeepSpeed(ZeRO)
👉🏻참고 링크 - Microsoft 블로그의 DeepSpeed 소개
👉🏻참고 링크 - PyTorch Lightning에서 DeepSpeed 사용
DeepSpeed란?
Microsoft에서 개발한 대규모 모델 학습을 위한 라이브러리다.
FSDP와 같이 PyTorch 내에서 native로 지원하지 않기 때문에 라이브러리를 따로 설치해야한다.
pip install deepspeed
DeepSpeed는 ZeRO(Zero Redundancy Optimizer)로도 불리우는데, optimizer states에 대한 GPU memory burden을 줄이는 것이 핵심이기 때문이다.
ZeRO는 stage 1, stage 2, stage 3, 총 3개의 stage가 있고, stage 2와 3은 offload 방법이 존재한다.
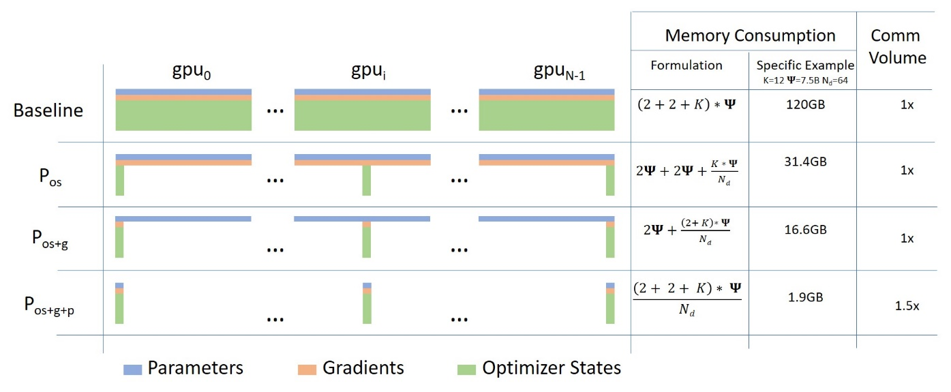
Stage 1
Stage 1의 핵심은 Optimizer States Partitioning이다.
Multi-GPU training에서 model을 GPU에 올릴 때 크게 parameters, gradients, optimizer states 3개로 구분할 수 있다.
여기서 optimizer states는 계산 부담이 큰 forward와 backward 연산에는 참여하지 않으면서, 메모리의 대부분을 차지한다.
optimizer states를 분산시켜 저장한다면, 연산 속도는 유지하면서 GPU 메모리를 상당히 절약할 수 있다.
Microsoft blog에 따르면 메모리를 최대 4배 절약할 수 있으며, PyTorch Lightning DeepSpeed 문서에 따르면 DDP와 동등한 속도를 유지하며, 메모리를 더욱 절약할 수 있다고 한다.
Stage 2
Stage 2는 Stage 1에 Gradients Partitioning을 더한 것이다.
Gradients까지 partitioning한다면 더욱 메모리를 절약할 수 있다.
Microsoft blog에 따르면 메모리를 최대 8배 절약할 수 있으며, PyTorch Lightning DeepSpeed 문서에 따르면 Gradients Partitioning으로 인한 GPU간 통신 비용의 증가에도 불구하고, DeepSpeed 팀의 최적화를 통해 DDP와 동등하거나 더 나은 속도를 제공하며, 메모리를 stage 1보다 더 절약할 수 있다고 한다.
이외에도 Activation Partitioning와 Fragmented memory를 도입했다.
Activation Partitioning
- Activation Partitioning을 적용하여 activation memory 복제 제거.
- Activation Memory를 CPU로 전송할 수 있음(offload).
Fragmented Memory
- 다양한 tensor의 수명 주기 때문에 학습 중에 메모리 단편화가 발생.
- 이로 인해 메모리가 충분하나 메모리 할당에 실패하는 경우 발생.
- Tensor의 서로 다른 수명을 기반으로 메모리를 관리하여 메모리 단편화 방지.
따라서 stage 2에서는 offload 옵션 사용 시, CPU로 메모리를 전송 및 연산하게 하여 메모리 공간을 더 확보할 수 있다.
from deepspeed.ops.adam import DeepSpeedCPUAdam
또한 위와 같이 CPU에 최적화된 Adam optimizer를 이용하여 연산 속도를 높일 수 있다(only GPU보다는 느림).
Stage 3
Stage 3은 Stage 2에 Parameters Partitioning을 더한 것이다.
Stage 3에서는 model의 모든 구성 요소를 다 쪼개는 것이다.
Microsoft blog에 따르면 메모리 절약 정도는 GPU 개수에 비례한다고 하며, 대규모 모델, 대규모 서버에 적용되면 모든 stage 중에 가장 메모리 효율적이다.
Stage 2와 같이 offload 옵션 사용 시, CPU로 메모리를 전송 및 연산하게 하여 메모리 공간을 더 확보할 수 있다.
from deepspeed.ops.adam import DeepSpeedCPUAdam
또한 위와 같이 CPU에 최적화된 Adam optimizer를 이용하여 연산 속도를 높일 수 있다(only GPU보다는 느림).
이외 추가 이점들
- Offload의 경우 single GPU에서도 사용 가능하고 GPU VRAM 공간을 더 확보할 수 있음(stage 2도 마찬가지).
- Infinity offload라 불리는 CPU와 NVMe 메모리를 모두 사용하여 엄청난 메모리 절약을 할 수 있음.
사용 방법(PyTorch Lightning)
PyTorch Lightning에서는 1.4 이상 버전부터 사용 가능하고, 1.9이상 버전부터 Trainer의 strategy=”deepspeed_stage_1”와 같이 간단히 적용할 수 있다.
deepspeed strategy의 옵션 목록은 다음과 같다.
- deepspeed_stage_1
- deepspeed_stage_2
- deepspeed_stage_2_offload
- deepspeed_stage_3
- deepspeed_stage_3_offload
from lightning.pytorch.strategies import DeepSpeedStrategy
해당 import 후, strategy 옵션을 조정할 수 있다.
프로젝트에서는 아직 시험 단계이고, DDP, FSDP, DeepSpeed를 모두 hydra-core 관리 하에 간단히 이용하고 싶어서 옵션을 상세 조정하지는 않았다.
DeepSpeed의 경우, DDP와 마찬가지로 설정한 batch size는 machine 전체의 batch size가 아닌, 각 process(GPU 1장)에 대한 batch size다.
주의 사항
Stage 3의 경우, Adam 또는 AdamW를 사용하는 경우, PyTorch의 native optimizer 대신 deepspeed.ops.adam의 FusedAdam 또는 DeepSpeedCPUAdam(CPU 오프로딩용)을 사용하는 것이 좋다.
Trainer class를 이용한 resumed training의 경우, checkpoint를 불러오는 것이 문제가 없지만, test의 경우는 문제가 된다.
Trainer의 load_checkpoint internal function을 이용해서 DeepSpeed의 load_checkpoint function으로 들어가는데, 오류 메세지와 깃허브의 DeepSpeed의 소스 코드를 확인해보니, offload 유무의 정보가 전달이 안되서, offload로 인식되고, case 처리에서 이상한 case로 빠져서 에러를 뱉는다.
따라서 test의 경우, rank에 따라 분산되어 저장되어있는 model states를 병합해야한다.
Stage 3의 경우, infinity offloading을 사용하려면, 아래 예시와 같이 하면 된다.
from lightning.pytorch import Trainer
from lightning.pytorch.strategies import DeepSpeedStrategy
# Enable CPU Offloading
model = MyModel()
trainer = Trainer(accelerator="gpu", devices=4, strategy="deepspeed_stage_3_offload", precision=16)
trainer.fit(model)
# Enable CPU Offloading, and offload parameters to CPU
model = MyModel()
trainer = Trainer(
accelerator="gpu",
devices=4,
strategy=DeepSpeedStrategy(
stage=3,
offload_optimizer=True,
offload_parameters=True,
remote_device="nvme",
offload_params_device="nvme",
offload_optimizer_device="nvme",
nvme_path="/local_nvme",
),
precision=16,
)
trainer.fit(model)
실험 결과
multimodal-transformer 프로젝트에서 약 216MB의 사이즈를 가지는 모델을 A100 40GB x 4에서 training 시켜봤다.
DDP, FSDP, DeepSpeed의 모든 stage에서 학습 시 유의미한 성능 변동은 일어나지 않았고, 모델의 사이즈가 작아서 그런지 DDP와 DeepSpeed의 모든 stage가 속도에서 유의미한 차이가 보이지 않았으며, stage 2, 3에 offload 적용 시 아주 미묘하게 느려졌다.
한가지 의아한 것은, FSDP가 기존 DDP보다도 약 5배나 느려졌다는 것이다.
예상 원인
- 모델의 사이즈가 너무 작으면 비효율적임.
- Dataloader에서 bottleneck
해당 프로젝트에서 dataloader의 경우, huggingface의 BERT 기반 모델을 각 modality에 대해 훈련시킨 후, 해당 모델로 각 modality에 대해 embedding을 multi-GPU에서 추론하는 과정을 포함한다.
미리 npy로 다 뽑아두면 되지만 당시 요구사항이 그러하여 어쩔 수 없이 그렇게 했는데, 아마 여기서 bottleneck이 생겼을 수도 있다.
어차피 곧 다가올 프로젝트에서 이런 bottleneck이 없는 규모가 훨씬 큰 모델을 다루게 되니, 그 때 정확한 비교가 가능할 것이다.
후기
호기심은 끝이 없다.
DDP만으로는 앞으로 진행할 프로젝트를 해결하기 힘듦도 있지만, 순수히 DDP를 조사하며 자연스럽게 model parallelism에 대해 관심이 가고 찾아봤다.
그래서 적용 및 실험하다가 프로젝트의 통일성 및 configure 옵션 정리, 직전 리팩토링에서 해결하지 못한 문제를 해결하고 싶어서 자연스럽게 또 대규모 리팩토링을 진행했다.
피곤하지만 재밌다. 다만, 여러 일을 같이하는 만큼 스케줄 관리를 더욱 꼼꼼히 해야할 것 같다.
그래도 궁금한건 못참아…!
댓글남기기