Optuna hyper-parameter search를 hydra-core로 관리해보자
Optuna with Hydra
👉🏻예시 깃허브 4((PyTorch Lightning))
이번 Upstage AI Lab 2기를 수강하며 EDA 프로젝트(예시 깃허브 1)에서 Optuna를 이용한 hyper parameter tuning을 진행했었다.
우선 hydra-core 없이 full cycle로 돌릴만한 코드를 작성 후 돌려보고, 이참에 기존에 사용하던 딥러닝 탬플릿 구조를 참고하여 machine learning - hydra 탬플릿을 만드는 김에, hydra로 optuna config를 조절하는 코드를 추가했고, 이전 석사 학위 연구에 사용했던 코드(예시 깃허브 2)도 같이 확장을 진행했다.
이렇게만 쓰면 아쉽지. 딥러닝 탬플릿도 이 참에 optuna hyper-parameter search를 처음 적용해보며, hydra로 config options를 control할 수 있도록 확장했다(예시 깃허브 3, 4).
다만, Hydra-core에서 제공해주는 Optuna sweeper plugin도 있고, 그걸 활용한 다른 프로젝트 혹은 탬플릿 예시도 구글 검색을 통해 찾아볼 수 있었으나 자체 tuning 코드를 작성하였다.
Hydra의 Optuna plugin을 쓰지 않은 이유
- sweeper를 통해 hparams를 결과와 같이 기록하지만, 원하는 형식으로 기록되지 않음
- best params만 json 형식으로 저장하여, tuning이 사전에 진행되었는지 조건문으로 체크하고, 조건==True라면, 자동으로 json 파일을 불러와서 적용되게끔 하고싶었음
- 위와 같은 이유 외에 내 입맛대로 커스텀하고 싶고, 모듈화하여 분리해놓고자 함
- LightGBM의 경우 Optuna integration에 LightGBMTunerCV라는, 모든 Cross Validation의 fold에 대해 최적 hparams를 search하는 기능이 있는데, LightGBM의 경험 상 XGBoost 등 다른 tree 기반 boosting 모델들에 비해 Optuna Search 속도가 빨라 적용해보고 싶었음.
주요 라이브러리
hydra-core==1.3.2
optuna==3.4.0
wandb
lightgbm
xgboost
pytorch-lightning==1.9.5
기본적인 Optuna의 사용법

위와 같이 objective function에 search하고자 하는 params들의 범위를 설정한다.
그리고 반드시 추적할 지표 결과를 return 해준다.
trial은 optuna.trial.Trial로, trial.suggest_{타입}으로 아래와 같이 선택할 수 있다.
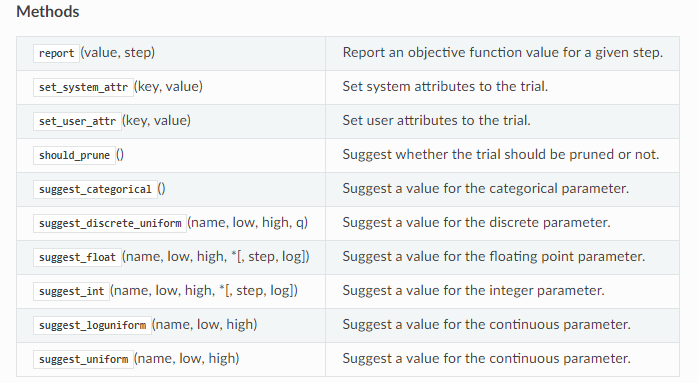
그리고 아래와 같이 hyper-parameter search 시도 횟수(n_trials), objective 결과를 추적하는 방식(direction), Sampler와 Pruner(optional)를 설정하고 돌리면, 결과의 .best_trial에서 .params와 .value에서 최적 hparams와 거기에 따른 스코어를 볼 수 있다.

여기서 direction은 일반적으로 rmse, logloss 등의 loss를 minimize하거나 accuracy, f1등의 score를 maximize하는 형식으로 설정하면 된다.
Hydra와의 접목(ML)
Hydra에서 hparams의 종류, 타입 등을 설정하고 그 외 direction n_trials 등을 .yaml 파일을 통해 관리하고, tuner_modules에서 불러오며, tune.py를 통해 tuning하고, train과 test에서 tuning된 hparams가 있다면 적용될 수 있게 했다.
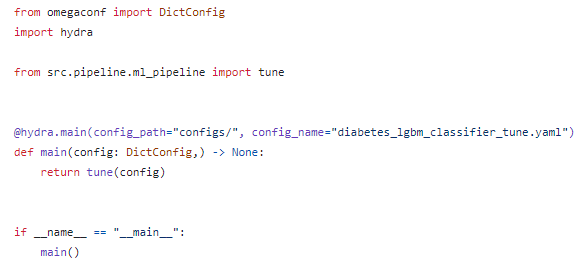
tune.py를 이용하여 hyper-parameter tuning 실행
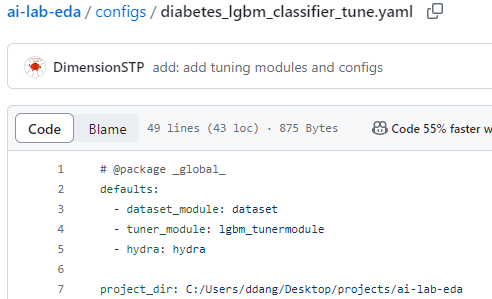
tune.py 실행 시 ~tune.yaml을 이용하여 tuner_module load
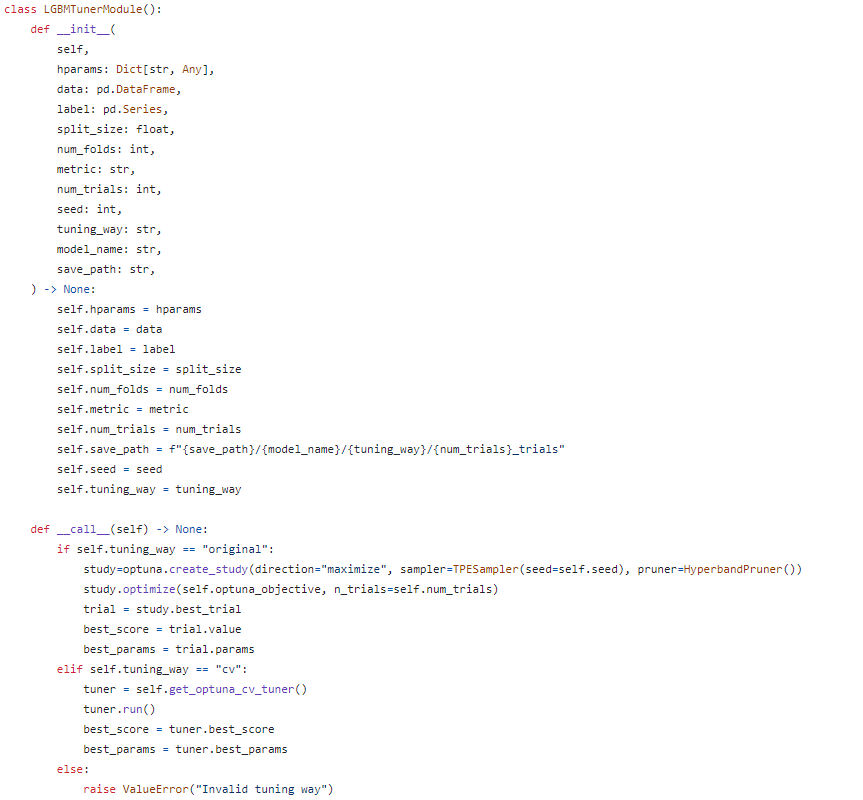


tuner_module 정의
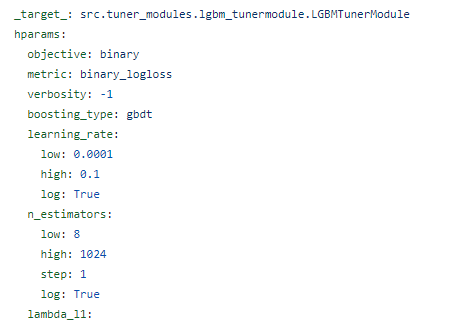
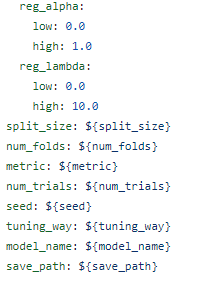
tuner_module/~tunermodule.yaml에서 hprams setting
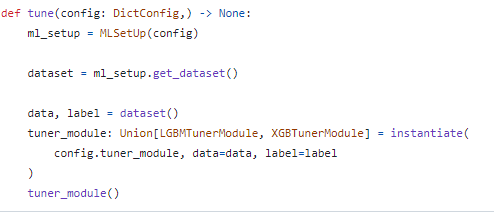
pipeline에서 tune 정의
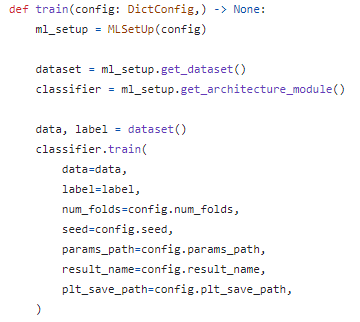

train에서 tuned params check 및 적용 기능 추가
자세한건 예시 깃허브 1, 2 참조.
ML의 경우 DL과 달리 Pytorch-Lightning등의 wrapper를 이용하여 LightningModule 등으로 감싸지 않고, 모델과 모델 학습 등의 모듈을 클래스 하나에 한번에 정의했기 때문에, utils의 setup에서 불러오기보다 바로 pipeline에서 hydra로 instantiate하는 방법을 선택했고, train에서 tuning을 통해 찾은 best_params.json이 있는지 체크하여 있다면 적용하는 기능을 추가했다.
Hydra와의 접목(DL)
DL의 경우 Pytoch-Lightning을 사용하기 때문에, optuna에서 권장하는 pytorch-lightning 예시 코드를 참조했다.
👉🏻예시 코드 링크
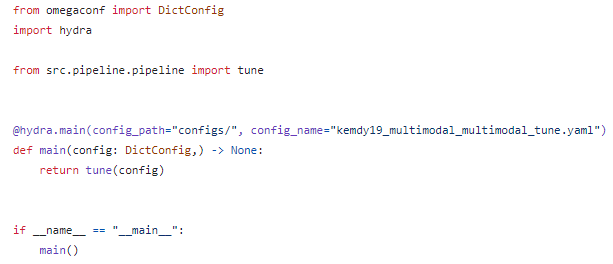
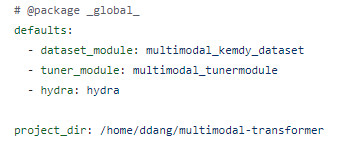
ML과 마찬가지로 tune.py와 ~tune.yaml을 이용하여 hyper-parameter tuning을 실행한다.



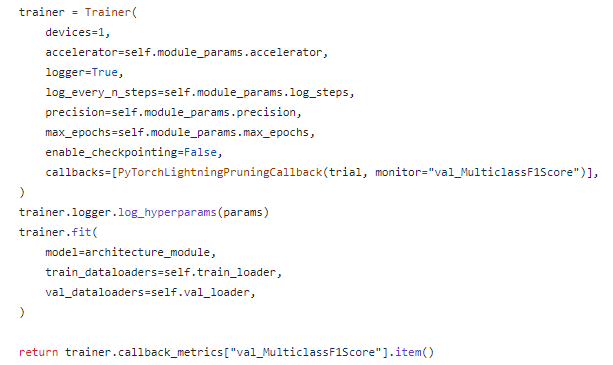
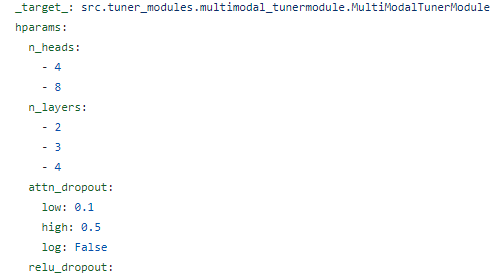
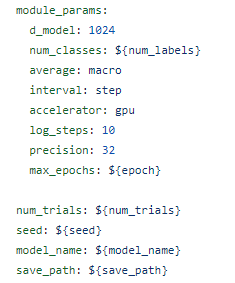
마찬가지로 ~tunermodule.py와 ~tunermodule.yaml을 이용하여 tuning 과정과 옵션을 정의한다.
다만, ML과의 차이는 Pytorch-Lightning를 사용하기 때문에 tunermodule 안에서 LightningModule과 Trainer를 인스턴스화 하고 실행까지하며, 거기에 따라 고정으로 들어가는 module_params도 정의해준다.
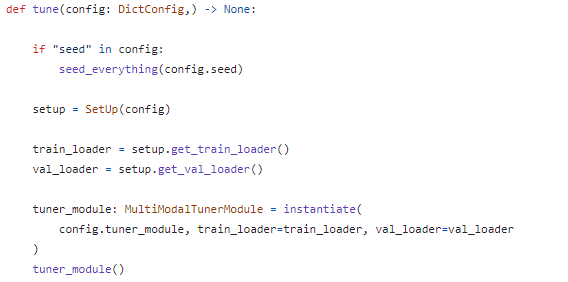
마찬가지로, pipeline에서 tune 함수를 정의해준다.
ML 때와 마찬가지로, tunermodule에서 LightningModule과 Trainer를 인스턴스화 하고 실행까지 하기 때문에 따로 utils의 setup에서 구현하진 않는다.
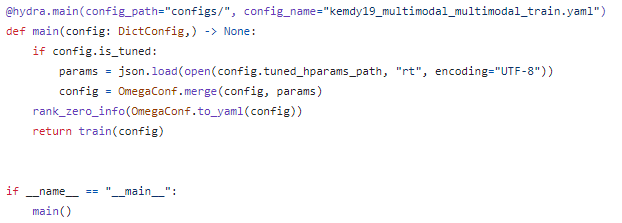
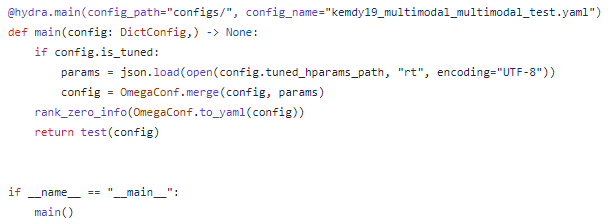

ML과는 달리 pipeline이 아닌 최종 실행 train.py, test.py에서 yaml의 is_tuned option을 체크해서 True라면, best_params.json을 불러와서 기존 config와 merge한다.
이런 식으로 구성한 이유는 더 간결하고, ML과 달리 Pytorch-Lightning을 씀으로써, model의 hparams만이 아닌 학습 단계에서 조절되는 optimizer와 scheduler의 lr, t_max, eta_min 등이 LightningModule에 따로 들어가야하기 때문이다.
또한 LightningModule에 argument로 들어갈 model instance에 한번, Trainer의 argument에 들어갈 LightningModule instance에 한번 들어가므로, train 뿐만 아니라, test나 predict.py와 .yaml에서도 같은 사항이 추가되어야 한다.
자세한건 예시 깃허브 3, 4 참조.
Optuna 적용까지의 과정
ML과 달리 Pytorch-Lightning, Optuna, Hydra-core가 version이 명시되어 있는 것은 이유가 있다.
version 간의 꼬임이 있기 때문이다.
현재 Pytorch-Lightning의 최신 버전은 2.1.3, Optuna는 3.5.0이다.
Optuna의 Pytorch-Lightning의 예시 코드를 보면 import문이 pytorch-lightning 1.9.x 버전을 쓰는 나에게 사뭇 어색하다.
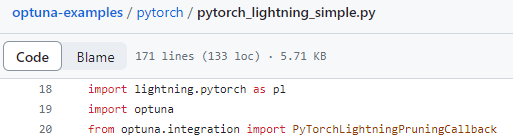
위와 같이 import lightning으로 시작하는데, 이러한 import 방식은 Pytorch-Lightning 2.0부터 가능한 import 형식이다.
예시 코드를 다시 한번 확인했던 이유는 역시 optuna 3.5 버전으로 실행 시 다음과 같은 에러가 났기 때문이다.

버전 3.5부터는 pytorch-lightning 2.0 이상을 지원하는 것을 확인했다.
위 링크처럼 같은 에러를 겪는 사람들이 존재한다.
하긴, lightning 2.0 출시 일자가 23년 3월이고 optuna 3.5 출시 일자가 23년 12월이니 당연하다.
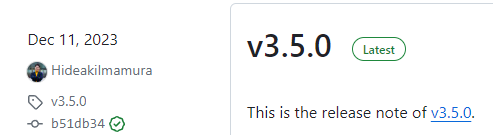
다만, 이전 버전의 pytorch-lightning integration을 지원해주지 않는 부분은 아쉽다.
해당 이슈는 #5028에서 확인 가능하고, commit log를 통해서도 더이상 1.x pytorch-lightning은 지원하지 않는 것을 확인했다.
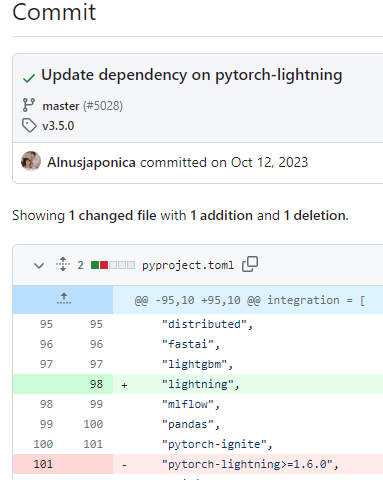
따라서, 버전을 다운그레이드했는데도, 문제가 발생했다.
Optuna 3.3와 3.4에서는 다음과 같은 에러가 발생했다.

확인해보니, 특정 버전 대의 pytorch-lightning에서 optuna의 특정 버전들은 DDP를 지원해주지 않는 것을 확인했다.
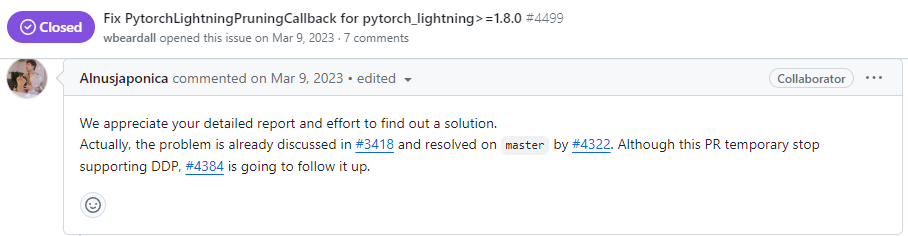
위 링크 2개를 참고하여, optuna 버전 2.x와 버전 3.0~3.2에서 될 수도 있겠다 판단하여 모든 버전을 실험해봤으나, 모두 다음과 같은 에러 중 1개를 마주하였다.


위 링크도 그렇고, 확인해보니 Pytorch-Ligtning version 1.8 이상에서 삭제된 기능 때문에 integration에서 에러가 발생한다.
결론은 pytorch-lightning 1.8 이상, 2.0 미만의 버전에서 optuna를 이용한 hyper-parameter tuning시 DDP를 지원해주는 optuna 버전이 없다는 것이다.
이로써 생기는 선택지는 아래와 같다.
- tune 부분만 pytorch-lightning 제외 구현
- pytorch-lightning을 1.8 미만으로 다운그레이드
- pytorch-lightning을 2.0 이상으로 업그레이드
- DDP 없이 우선 진행
애초에 템플릿을 만드는 목적이 강했기 때문에 pytorch-lightning 제외는 하지 않고, 1.8 미만으로 다운그레이드는 이미 한번 hydra-core와 버전을 맞추느라, 그리고 LightningModule의 epoch_end function 등을 수정해야해서 템플릿의 변경을, 2.0 이상 업그레이드는 import 문 변경은 차처하더라도, 현재의 python, pytorch 버전에서 불가능해서 더이상의 공수를 쏟고 싶지 않아 DDP를 사용하지 않는걸로 결정, single GPU로 잘 적용되는 것을 확인하고 마무리했다.
후기
얼마 전 DL 프로젝트 템플릿에 대해 리팩토링을 진행했다.
해당 글에서 hydra-core==1.3.2, pytorch_lightning==1.9.5에 정착했는데, lightning 2.0 이상의 버전을 적용하지 못한 이유는 아래의 버전을 지원하는 lightning 2.0 이상의 버전이 없었기 때문이다.
- python 3.7.x 버전 사용
- pytorch 1.x 버전 사용
python과 pytorch 버전 업그레이드시 더욱 대대적인 개편이 필요하다.
python 버전을 왜 아직 3.7.x 버전을 고수했는지 생각해보니, 예시 깃허브 링크 3에서 생성한 데이터 pkl 파일이 python 3.8 이상에서 pickle protocol이 4->5로 변경됨으로 열리지 않기 때문이었다.
이제 슬슬 python 3.7.x를 지원하는 라이브러리들이 줄어들고 있다.
지금도 DL 프로젝트를 제외한 대부분은 python 3.8.x 버전의 가상환경을 사용하고 있고, google colab도 약 1년 전에 base python version을 3.8로 올린걸 확인했던 기억이 있다.
언젠가 다시 대대적인 리팩토링을 거쳐할 것 같다.
pkl의 경우도 그렇고, ML 프로젝트에서 csv 파일의 encoding이나, 이번 optuna best params search 결과를 json으로 저장할 때, ML의 경우는 윈도우 기반 개인 로컬 컴퓨터에서 DL의 경우 한글 지원이 되지 않는 우분투 서버에서 실험했는데, 윈도우 기반 로컬 컴퓨터는 인코딩을 지정하는걸 깜빡하니 영어와 숫자밖에 없어도 cp949로 저장되어 귀찮게했다.
tune 단계에서 이미 결과가 쌓였고, train 단계에서 issue를 확인해서, json 파일을 불러올 때 open 함수 안에 싸서 open에서 encoding을 utf-8로 맞추는 것으로 해결했지만, 항상 버전과 encoding, 그리고 자주 사용하는 라이브러리들의 주기적인 release note 확인이 중요하다는 것을 상기하게됐다.
댓글남기기